[TOC]
MySQL
数据库存储引擎有哪些?
- InnoDB
- Myisam
- Memory
说明:
- InnoDB,Myisam的默认索引是
B+Tree,Memory的默认索引是hash - InnoDB支持事务,支持外键,支持行锁,写入数据时操作快,MySQL5.6版本以上才支持全文索引
- Myisam不支持事务。不支持外键,支持表锁,支持全文索引,读取数据快
- Memory所有的数据都保留在内存中,不需要进行磁盘的IO所以读取的速度很快;但是一旦关机,表的结构会保留但是数据就会丢失;表支持Hash索引,因此查找速度很快
数据库架构图(需手写)
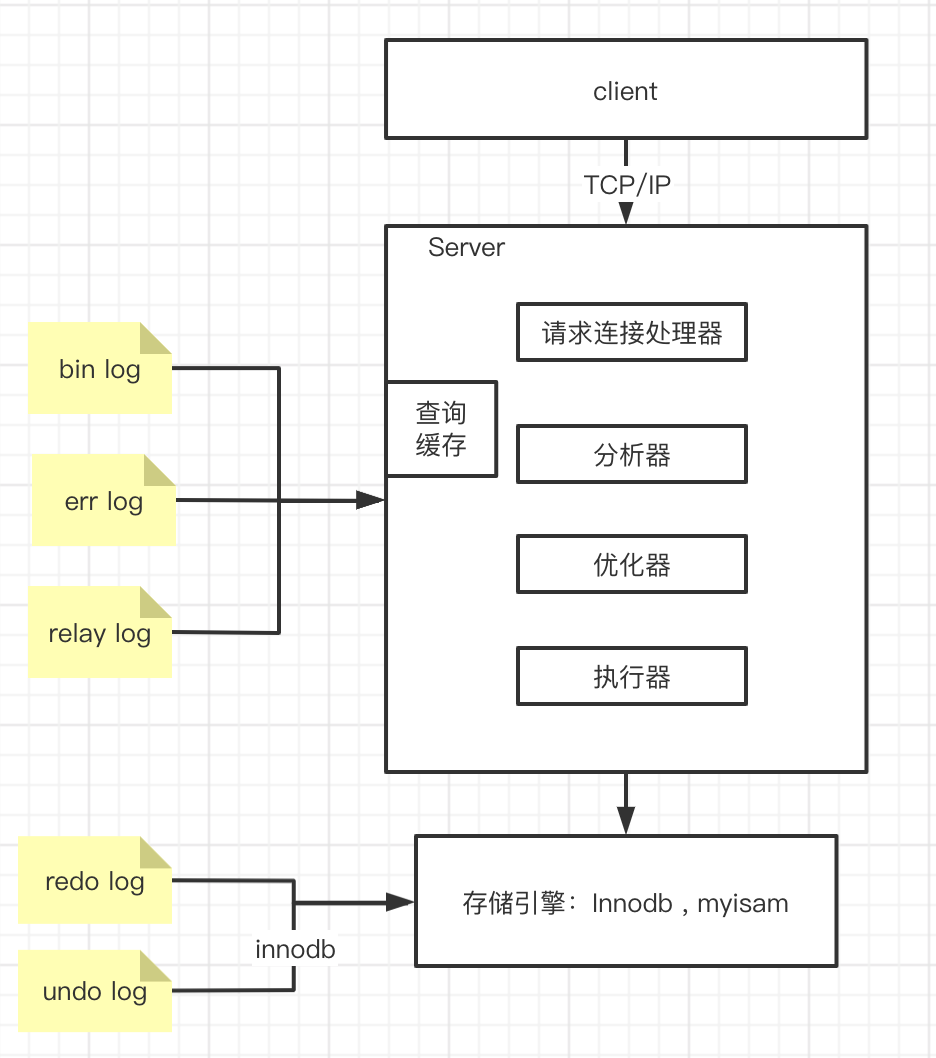

数据库基础
存储过程
创建和使用例子
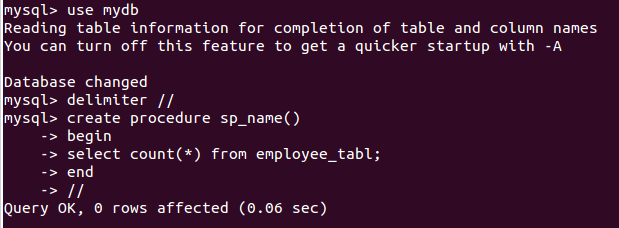
- 使用
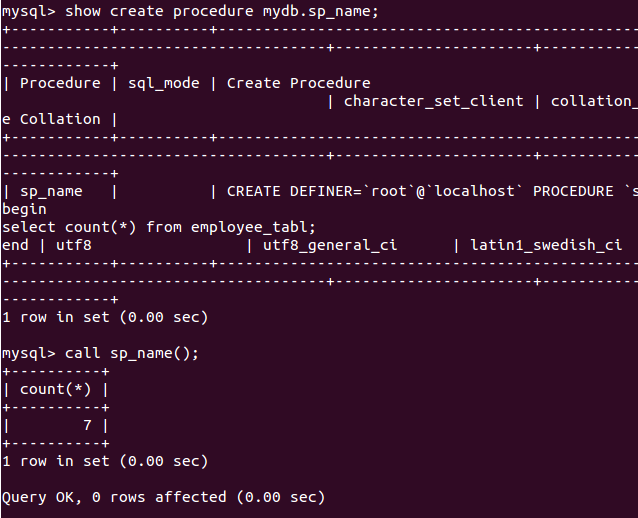
存储过程的优点
- 运行速度:对于很简单的sql,存储过程没有什么优势。对于复杂的业务逻辑,因为在存储过程创建的时候,数据库已经对其进行了一次解析和优化。存储过程一旦执行,在内存中就会保留一份这个存储过程,这样下次再执行同样的存储过程时,可以从内存中直接调用,所以执行速度会比普通sql快。
- 减少网络传输:存储过程直接就在数据库服务器上跑,所有的数据访问都在数据库服务器内部进行,不需要传输数据到其它服务器,所以会减少一定的网络传输。但是在存储过程中没有多次数据交互,那么实际上网络传输量和直接sql是一样的。而且我们的应用服务器通常与数据库是在同一内网,大数据的访问的瓶颈会是硬盘的速度,而不是网速。
- 可维护性:存储过程有些时候比程序更容易维护,这是因为可以实时更新DB端的存储过程。有些bug,直接改存储过程里的业务逻辑,就搞定了。
- 增强安全性:提高代码安全,防止
SQL注入。这一点Sql语句也可以做到。 - 可扩展性:应用程序和数据库操作分开,独立进行,而不是相互在一起。方便以后的扩展和DBA维护优化。
存储过程的缺点
- SQL本身是一种结构化查询语言,但不是面向对象的,本质上还是过程化的语言,面对复杂的业务逻辑,过程化的处理会很吃力。同时SQL擅长的是数据查询而非业务逻辑的处理,如果如果把业务逻辑全放在存储过程里面,违背了这一原则。
- 如果需要对输入存储过程的参数进行更改,或者要更改由其返回的数据,则您仍需要更新程序集中的代码以添加参数、更新调用,等等,这时候估计会比较繁琐了。
- 开发调试复杂,由于IDE的问题,存储过程的开发调试要比一般程序困难。
- 没办法应用缓存。虽然有全局临时表之类的方法可以做缓存,但同样加重了数据库的负担。如果缓存并发严重,经常要加锁,那效率实在堪忧。
- 不支持集群,数据库服务器无法水平扩展,或者数据库的切割(水平或垂直切割)。数据库切割之后,存储过程并不清楚数据存储在哪个数据库中。
数据库范式
第一范式
每个属性都不可再分

第二范式
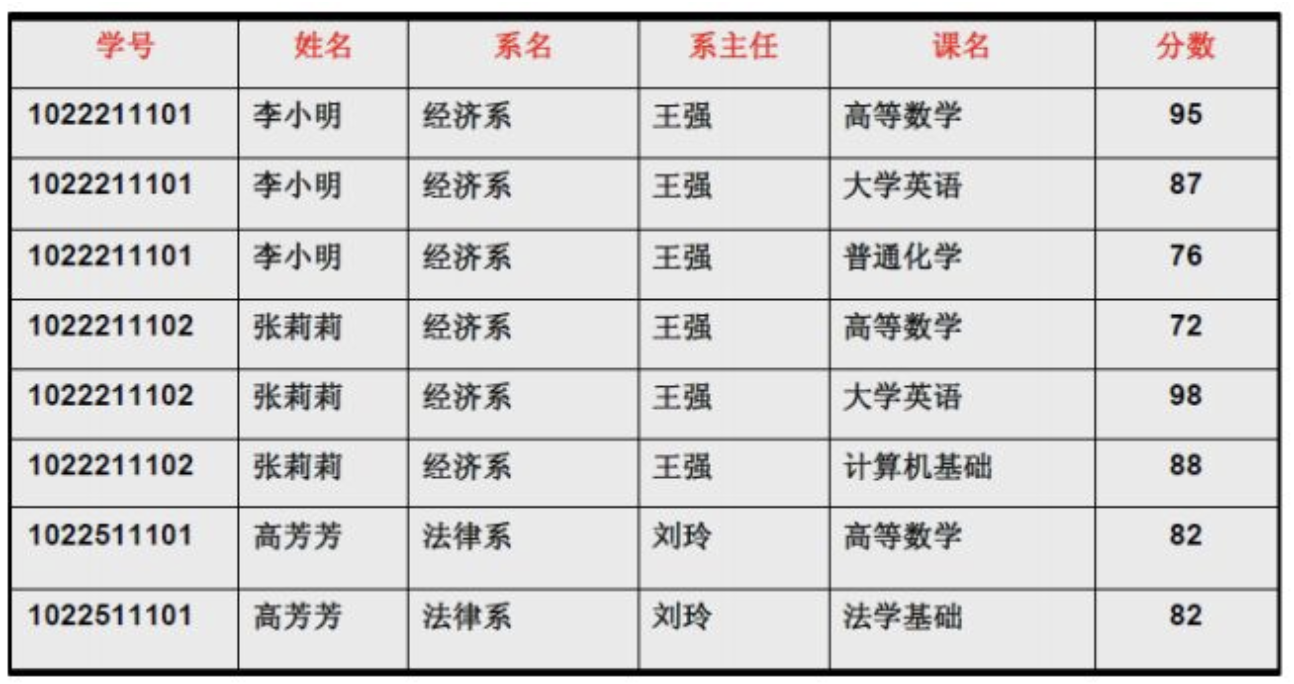
每一名学生的学号、姓名、系名、系主任这些数据重复多次。每个系与对应的系主任的数据也重复多次——数据冗余过大
假如学校新建了一个系,但是暂时还没有招收任何学生(比如3月份就新建了,但要等到8月份才招生),那么是无法将系名与系主任的数据单独地添加到数据表中去的 (注1)——插入异常
注1:根据三种关系完整性约束中实体完整性的要求,关系中的码(注2)所包含的任意一个属性都不能为空,所有属性的组合也不能重复。为了满足此要求,图中的表,只能将学号与课名的组合作为码,否则就无法唯一地区分每一条记录
码:关系中的某个属性或者某几个属性的组合,用于区分每个元组(可以把“元组”理解为一张表中的每条记录,也就是每一行)。
假如将某个系中所有学生相关的记录都删除,那么所有系与系主任的数据也就随之消失了(一个系所有学生都没有了,并不表示这个系就没有了)。删除异常
假如李小明转系到法律系,那么为了保证数据库中数据的一致性,需要修改三条记录中系与系主任的数据。——修改异常
"若在一张表中,在属性(或属性组)X的值确定的情况下,必定能确定属性Y的值,那么就可以说Y函数依赖于X,写作X → Y"
第二范式:在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)
- 选课(学号,课名,分数)
- 学生(学号,姓名,系名,系主任)
对于选课表,其码是(学号,课名),主属性是学号和课名,非主属性是分数,学号确定,并不能唯一确定分数,课名确定,也不能唯一确定分数,所以不存在非主属性分数对于码 (学号,课名)的部分函数依赖,所以此表符合2NF的要求。
对于学生表,其码是学号,主属性是学号,非主属性是姓名、系名和系主任,因为码只有一个属性,所以不可能存在非主属性对于码 的部分函数依赖,所以此表符合2NF的要求。
第三范式
在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
- 学生(学号,姓名,系名,系主任)
对于学生表,主码为学号,主属性为学号,非主属性为姓名、系名和系主任。因为 学号 → 系名,同时 系名 → 系主任,所以存在非主属性系主任对于码学号的传递函数依赖,所以学生表的设计,不符合3NF的要求。
- 选课(学号,课名,分数)
- 学生(学号,姓名,系名)
- 系(系名,系主任)

BCNF范式
巴斯-科德范式(BCNF)是第三范式(3NF)的一个子集,即满足巴斯-科德范式(BCNF)必须满足第三范式(3NF)。通常情况下,巴斯-科德范式被认为没有新的设计规范加入,只是对第二范式与第三范式中设计规范要求更强,因而被认为是修正第三范式,也就是说,它事实上是对第三范式的修正,使数据库冗余度更小。这也是BCNF不被称为第四范式的原因
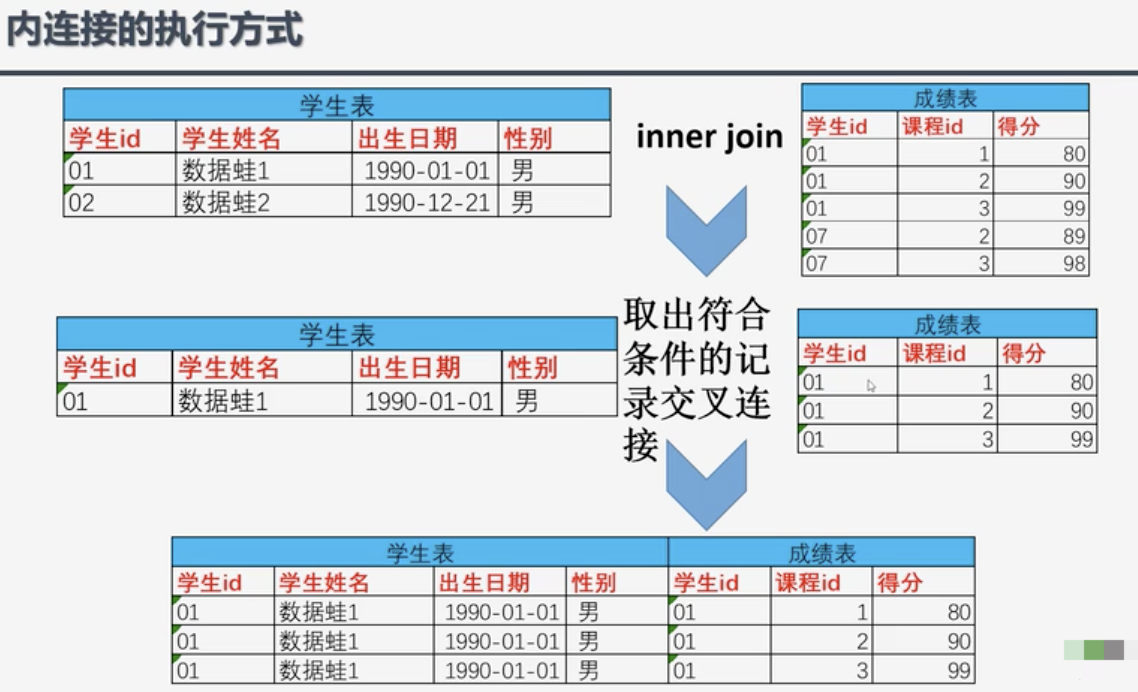
数据表join操作

- INNER JOIN: 内连接是最常见的一种连接,只连接匹配的行
- LEFT JOIN: 返回左表的全部行和右表满足ON条件的行,如果左表的行在右表中没有匹配,那么这一行右表中对应数据用NULL代替
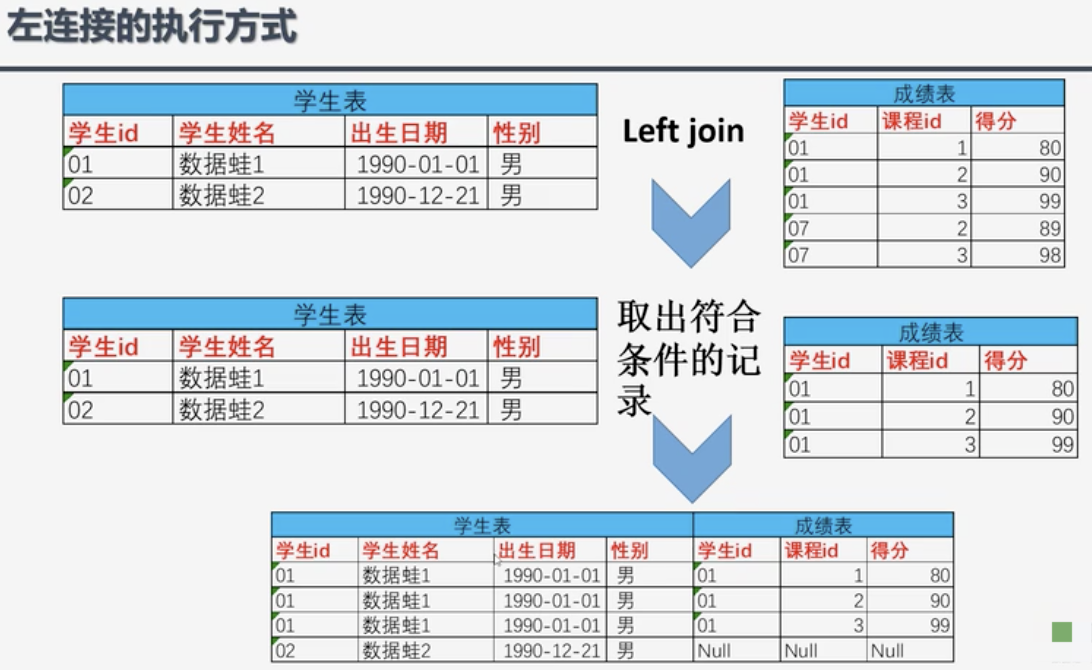
table1 table2
id size size name
1 10 10 AAA
2 20 20 BBB
3 30 20 CCC
select * form tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name = 'AAA'
会生成一个中间表
tab1.id tab1.size tab2.size tab2.name
1 10 10 AAA
2 20 20 BBB
2 20 20 CCC
3 30 (null) (null)
然后再用tab2.name = 'AAA'进行过滤
tab1.id tab1.size tab2.size tab2.name
1 10 10 AAA
select * form tab1 left join tab2 on (tab1.size = tab2.size and tab2.name = 'AAA')
中间表如下(也是最后的结果),即:条件不为真(tab2.name = 'AAA')也会返回左表中的记录
tab1.id tab1.size tab2.size tab2.name
1 10 10 AAA
2 20 (null) (null)
3 30 (null) (null)
总结:不管on上的条件是否为真,对left join, right join, full join都会返回left或right表中的记录
RIGHT JOIN: 返回右表的全部行和左表满足ON条件的行,如果右表的行在左表中没有匹配,那么这一行左表中对应数据用NULL代替
FULL OUTER JOIN: 会从左表 和右表 那里返回所有的行。如果其中一个表的数据行在另一个表中没有匹配的行,那么对面的数据用NULL代替
CROSS JOIN: 把表A和表B的数据进行一个N*M的组合,即笛卡尔积
多表连接的三种方式详解 hash join、merge join、nested loop
nested loop(嵌套循环)
驱动表(也叫外表)和被驱动表(也叫非驱动表,还可以叫匹配表,亦可叫内表),简单来说,驱动表就是主表,left join 中的左表就是驱动表,right join 中的右表是驱动表。一个是驱动表,那另一个就只能是非驱动表了
在 join 的过程中,其实就是从驱动表里面依次(注意理解这里面的依次)取出每一个值,然后去非驱动表里面进行匹配,那具体是怎么匹配的呢?这就是我们接下来讲的这三种连接方式:
(Simple Nested-Loop Join )暴力匹配的方式;如果 table A 有10行,table B 有10行,总共需要执行10 x 10 = 100次查询
(Index Nested-Loop Join)这个 Index 是要求非驱动表上要有索引,有了索引以后可以减少匹配次数,匹配次数减少了就可以提高查询的效率了,eg:左边就是普通列的存储方式,右边是树结构索引, 能减少查询次数
(Block Nested-Loop Join)
理想情况下,用索引匹配是最高效的一种方式,但是在现实工作中,并不是所有的列都是索引列,这个时候就需要用到 Block Nested-Loop Join 方法了,这种方法与第一种方法比较类似,唯一的区别就是:会把驱动表中 left join 涉及到的所有列(不止是用来on的列,还有select部分的列)先取出来放到一个缓存区域,然后再去和非驱动表进行匹配,这种方法和第一种方法相比所需要的匹配次数是一样的,差别就在于驱动表的列数不同,也就是数据量的多少不同。所以虽然匹配次数没有减少,但是总体的查询性能还是有提升的。
适用于小表与小表的连接
Hash Join
hash join仅仅在join的字段上没有索引时才起作用,在此之前,我们不建议在没有索引的字段上做join操作,因为通常中这种操作会执行得很慢,但是有了hash join,它能够创建一个内存中的hash表,代替之前的nested loop,使得没有索引的等值join性能提升很多。
- 配置hash join功能是否开启:
- optimizer_switch 中的 hash_join=on/off,默认为on
- sql语句中指定HASH_JOIN或者NO_HASH_JOIN
限制:
- hash join只能在没有索引的字段上有效
- hash join只在等值join条件中有效
- hash join不能用于left join和right join
适用于小表与大表的连接
merge join
merge join第一个步骤是确保两个关联表都是按照关联的字段进行排序。如果关联字段有可用的索引,并且排序一致,则可以直接进行merge join操作;
两个表都按照关联字段排序好之后,merge join操作从每个表取一条记录开始匹配,如果符合关联条件,则放入结果集中;否则,将关联字段值较小的记录抛弃,从这条记录对应的表中取下一条记录继续进行匹配,直到整个循环结束。
function sortMerge(relation left, relation right, attribute a)
var relation output
var list left_sorted := sort(left, a) // Relation left sorted on attribute a
var list right_sorted := sort(right, a)
var attribute left_key, right_key
var set left_subset, right_subset // These sets discarded except where join predicate is satisfied
advance(left_subset, left_sorted, left_key, a)
advance(right_subset, right_sorted, right_key, a)
while not empty(left_subset) and not empty(right_subset)
if left_key = right_key // Join predicate satisfied
add cartesian product of left_subset and right_subset to output
advance(left_subset, left_sorted, left_key, a)
advance(right_subset, right_sorted, right_key, a)
else if left_key < right_key
advance(left_subset, left_sorted, left_key, a)
else // left_key > right_key
advance(right_subset, right_sorted, right_key, a)
return output
// Remove tuples from sorted to subset until the sorted[1].a value changes
function advance(subset out, sorted inout, key out, a in)
key := sorted[1].a
subset := emptySet
while not empty(sorted) and sorted[1].a = key
insert sorted[1] into subset
remove sorted[1]
merge join操作本身是非常快的,但是merge join前进行的排序可能会相当耗时
它首先根据R和S的join key分别对两张表进行排序,然后同时遍历排序后的R和S
其I/O复杂度可以表示为O[p(R) + p(S) + p(R) · logp(R) + p(S) · logp(S)]
附:归并排序是稳定排序,最好,最坏,平均时间复杂度均为O(nlogn)。
Mysql查询优化
开启优化器:set profiling=1;,粗粒度的要被废弃
- profiling默认关闭,如下
mysql> show variables like "%pro%";
+------------------------------------------+-------+
| Variable_name | Value |
+------------------------------------------+-------+
| check_proxy_users | OFF |
| have_profiling | YES |
| mysql_native_password_proxy_users | OFF |
| performance_schema_max_program_instances | -1 |
| profiling | OFF |
| profiling_history_size | 15 |
| protocol_version | 10 |
| proxy_user | |
| sha256_password_proxy_users | OFF |
| slave_compressed_protocol | OFF |
| stored_program_cache | 256 |
+------------------------------------------+-------+
11 rows in set (0.04 sec)
查看profile的部分查询信息
mysql> show profiles;
+----------+------------+------------------------+
| Query_ID | Duration | Query |
+----------+------------+------------------------+
| 1 | 0.00010400 | show database |
| 2 | 0.00786000 | show databases |
| 3 | 0.00614300 | SELECT DATABASE() |
| 4 | 0.00033500 | show databases |
| 5 | 0.00045300 | show tables |
| 6 | 0.00033800 | show tables |
| 7 | 0.01054800 | select * from sk_goods |
+----------+------------+------------------------+
7 rows in set, 1 warning (0.00 sec)
mysql>
mysql>
mysql>
mysql> show profile cpu for query 7;
+----------------------+----------+----------+------------+
| Status | Duration | CPU_user | CPU_system |
+----------------------+----------+----------+------------+
| starting | 0.006655 | 0.000061 | 0.000413 |
| checking permissions | 0.000011 | 0.000005 | 0.000006 |
| Opening tables | 0.000016 | 0.000014 | 0.000001 |
| init | 0.000036 | 0.000016 | 0.000021 |
| System lock | 0.000033 | 0.000013 | 0.000017 |
| optimizing | 0.000009 | 0.000004 | 0.000005 |
| statistics | 0.000025 | 0.000014 | 0.000007 |
| preparing | 0.000038 | 0.000013 | 0.000014 |
| executing | 0.000003 | 0.000001 | 0.000001 |
| Sending data | 0.003676 | 0.000105 | 0.000916 |
| end | 0.000008 | 0.000003 | 0.000005 |
| query end | 0.000006 | 0.000004 | 0.000001 |
| closing tables | 0.000007 | 0.000008 | 0.000004 |
| freeing items | 0.000016 | 0.000006 | 0.000006 |
| cleaning up | 0.000009 | 0.000008 | 0.000001 |
+----------------------+----------+----------+------------+
15 rows in set, 1 warning (0.01 sec)
mysql>
mysql> show profile all for query 7;
+----------------------+----------+----------+------------+-------------------+---------------------+--------------+---------------+---------------+-------------------+-------------------+-------------------+-------+-----------------------+----------------------+-------------+
| Status | Duration | CPU_user | CPU_system | Context_voluntary | Context_involuntary | Block_ops_in | Block_ops_out | Messages_sent | Messages_received | Page_faults_major | Page_faults_minor | Swaps | Source_function | Source_file | Source_line |
+----------------------+----------+----------+------------+-------------------+---------------------+--------------+---------------+---------------+-------------------+-------------------+-------------------+-------+-----------------------+----------------------+-------------+
| starting | 0.006655 | 0.000061 | 0.000413 | 0 | 10 | 0 | 0 | 0 | 0 | 6 | 0 | 0 | NULL | NULL | NULL |
| checking permissions | 0.000011 | 0.000005 | 0.000006 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | check_access | sql_authorization.cc | 809 |
| Opening tables | 0.000016 | 0.000014 | 0.000001 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | open_tables | sql_base.cc | 5753 |
| init | 0.000036 | 0.000016 | 0.000021 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | handle_query | sql_select.cc | 128 |
| System lock | 0.000033 | 0.000013 | 0.000017 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | mysql_lock_tables | lock.cc | 330 |
| optimizing | 0.000009 | 0.000004 | 0.000005 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | optimize | sql_optimizer.cc | 158 |
| statistics | 0.000025 | 0.000014 | 0.000007 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | optimize | sql_optimizer.cc | 374 |
| preparing | 0.000038 | 0.000013 | 0.000014 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | optimize | sql_optimizer.cc | 482 |
| executing | 0.000003 | 0.000001 | 0.000001 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | exec | sql_executor.cc | 126 |
| Sending data | 0.003676 | 0.000105 | 0.000916 | 0 | 20 | 0 | 0 | 0 | 0 | 46 | 10 | 0 | exec | sql_executor.cc | 202 |
| end | 0.000008 | 0.000003 | 0.000005 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | handle_query | sql_select.cc | 206 |
| query end | 0.000006 | 0.000004 | 0.000001 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | mysql_execute_command | sql_parse.cc | 4956 |
| closing tables | 0.000007 | 0.000008 | 0.000004 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | mysql_execute_command | sql_parse.cc | 5009 |
| freeing items | 0.000016 | 0.000006 | 0.000006 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | mysql_parse | sql_parse.cc | 5622 |
| cleaning up | 0.000009 | 0.000008 | 0.000001 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | dispatch_command | sql_parse.cc | 1931 |
+----------------------+----------+----------+------------+-------------------+---------------------+--------------+---------------+---------------+-------------------+-------------------+-------------------+-------+-----------------------+----------------------+-------------+
15 rows in set, 1 warning (0.00 sec)
mysql>
避免向数据库请求不必要的数据
比如:1. 避免select *;2. 避免假分页查询
请求多余的行会增加CPU,内存,和网络开销
使用索引
大查询分解,Join查询分解
大量查询匹配项,使用In替代Or
排序优化,尽量使用索引
子查询优化
正确使用联合索引
正确使用联合索引
innoDb
B+树一般几层?
innoDB 中页的默认大小是 16KB
假设一行记录的数据大小为1k,那么单个叶子节点(页)中的记录数=16K/1K=16
非叶子节点能存放多少指针?假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,一个页中能存放多少这样的单元,其实就代表有多少指针,即16kb/14b=1170;那么可以算出一棵高度为2的B+树,大概能存放1170*16=18720条这样的数据记录(即1170个索引,每个索引定位叶子节点的一页数据,一页能存储16行原始数据)。
根据同样的原理我们可以算出一个高度为3的B+树大概可以存放:1170*1170*16=21,902,400行数据。所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。在查找数据时一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次逻辑IO操作即可查找到数据。
页(Page)是 Innodb 存储引擎用于管理数据的最小磁盘单位
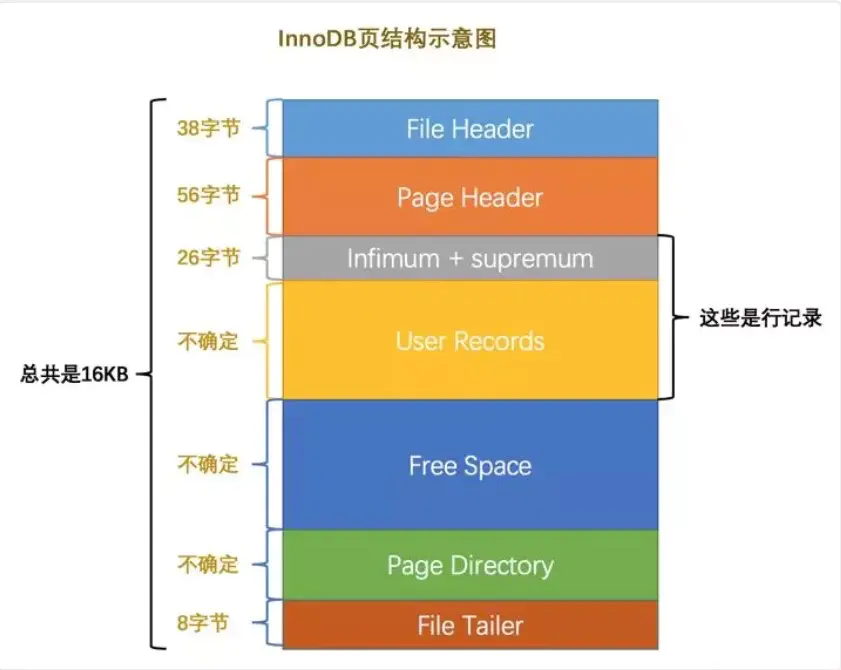
- File Header: 文件头部,页的一些通用信息(38字节)
- page Header: 页面头部,数据页专有的一些信息(56字节)
- infimum+supremum: 行记录最小值和最大值,两个虚拟的行记录(26字节)
- user recorders: 实际存储的行记录内容(不确定)
- free space: 页中尚未使用的空间(不确定)
- Page Directory: 页中的某些记录的相对位置(不确定)
- File Tailer: 校验页是否完整(8字节)
记录在页中的存储
- 当一个记录需要插入页的时候,会从
Free space划分空间到User recorders Free Space部分的空间全部被User Records部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了
innodb ibd文件
ibd文件是以页为单位进行管理的,页通常是以16k为单位,所以ibd文件通常是16k的整数倍
innodb 页类型
| 名称 | 十六进制 | 解释 |
|---|---|---|
| FIL_PAGE_INDEX | 0x45BF | B+树叶节点 |
| FIL_PAGE_UNDO_LOGO | 0x0002 | UNDO LOG页 |
| FIL_PAGE_INODE | 0x0003 | 索引节点 |
| FIL_PAGE_IBUF_FREE_LIST | 0x0004 | InsertBuffer空闲列表 |
| FIL_PAGE_TYPE_ALLOCATED | 0x0000 | 该页的最新分配 |
| FIL_PAGE_IBUF_BITMAP | 0x0005 | InsertBuffer位图 |
| FIL_PAGE_TYPE_SYS | 0x0006 | 系统页 |
| FIL_PAGE_TYPE_TRX_SYS | 0x0007 | 事务系统数据 |
| FIL_PAGE_TYPE_FSP_HDR | 0x0008 | FILE SPACE HEADER |
| FIL_PAGE_TYPE_XDES | 0x0009 | 扩展描述页 |
| FIL_PAGE_TYPE_BLOB | 0x000A | BLOB页 |
分析ibd文件
mubi@mubideMacBook-Pro bin $ mysql -uroot -p123456
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 109
Server version: 5.6.40 MySQL Community Server (GPL)
Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> use test;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from tb_user;
+------------+--------+----------+-------+-------------+----------+
| id | userID | password | name | phone | address |
+------------+--------+----------+-------+-------------+----------+
| 1 | 00001 | 123456 | zhang | 15133339999 | Shanghai |
| 2 | 00002 | 123456 | wang | 15133339999 | Beijing |
| 4 | 0003 | NULL | abc | NULL | NULL |
| 6 | 0003 | NULL | abc | NULL | NULL |
| 7 | 0004 | 123456 | tom | 110 | beijing |
| 10 | 0004 | 123456 | tom | 110 | beijing |
| 2147483647 | 0004 | 123456 | tom | 110 | beijing |
+------------+--------+----------+-------+-------------+----------+
7 rows in set (0.00 sec)
mysql>
查看数据表的行格式
mysql> show table status like 'tb_user'\G;
*************************** 1. row ***************************
Name: tb_user
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 6
Avg_row_length: 2730
Data_length: 16384
Max_data_length: 0
Index_length: 16384
Data_free: 0
Auto_increment: 2147483647
Create_time: 2020-03-21 16:10:06
Update_time: NULL
Check_time: NULL
Collation: utf8_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
ERROR:
No query specified
mysql>
查看ibd文件

使用py_innodb_page_info工具(https://github.com/happieme/py_innodb_page_info)
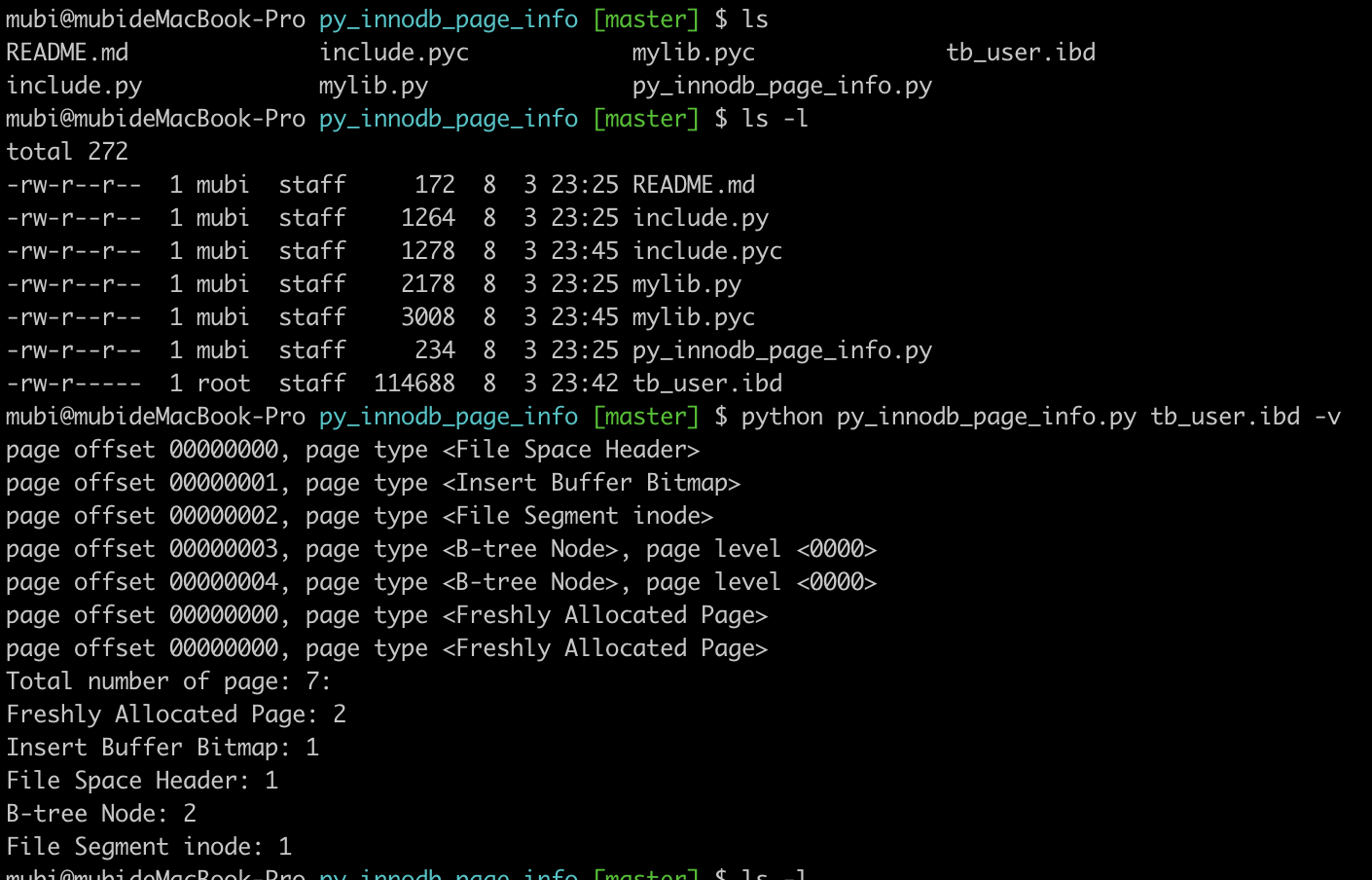
注意到文件大小114688字节(114688 = 16 1024 7)即有7个页(要分析哪个页直接定位到二进制文件到开始,然后分析即可)
分析第4个页:B-tree Node类型
page offset 00000003, page type <B-tree Node>, page level <0000>
>>> hex(3 * 16 * 1024)
'0xc000'
>>> hex(4 * 16 * 1024)
'0x10000'
>>>
先分析File Header(38字节-描述页信息)

- 2D A1 2D 57 -> 数据页的checksum值
- 00 00 00 03 -> 页号(偏移量),当前是第3页
- FF FF FF FF -> 目前只有一个数据页,无上一页
- FF FF FF FF -> 目前只有一个数据页,无下一页
- 00 00 00 04 6F 65 24 CF -> 该页最后被修改的LSN
- 45 BF -> 页的类型,0x45BF代表数据页,刚好这页是数据页
- 00 00 00 00 00 00 00 00 -> 独立表空间,该值为0
- 00 00 00 06 -> 表空间的SPACE ID
再分析Page Header(56字节-记录页的状态信息)
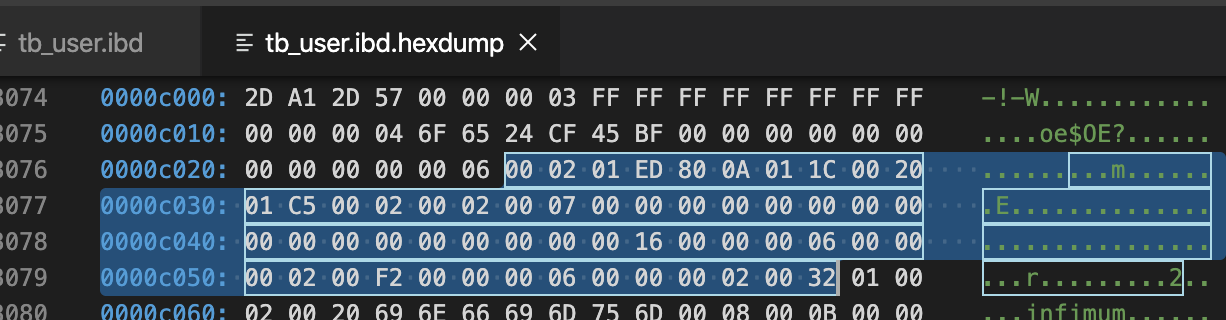
| 标识 | 字节数 | 解释 | 本次值:说明 |
|---|---|---|---|
| PAGE_N_DIR_SLOTS | 2 | number of directory slots in the Page Directory part; initial value = 2 | 00 02,2个槽位 |
| PAGE_HEAP_TOP | 2 | record pointer to first record in heap | 01 ED,堆第一个开始位置的偏移量,也即空闲偏移量 |
| PAGE_N_HEAP | 2 | number of heap records; initial value = 2 | 80 0A |
| PAGE_FREE | 2 | record pointer to first free record | 01 1C |
| PAGE_GARBAGE | 2 | "number of bytes in deleted records" | 00 20,删除的记录字节 |
| PAGE_LAST_INSERT | 2 | record pointer to the last inserted record | 01 C5,最后插入记录的位置偏移 |
| PAGE_DIRECTION | 2 | either PAGE_LEFT, PAGE_RIGHT, or PAGE_NO_DIRECTION | 00 02,自增长的方式进行行记录的插入,方向向右 |
| PAGE_N_DIRECTION | 2 | number of consecutive inserts in the same direction, for example, "last 5 were all to the left" | 00 02 |
| PAGE_N_RECS | 2 | number of up[ser records | 00 07,共7条有效记录数 |
| PAGE_MAX_TRX_ID | 8 | the highest ID of a transaction which might have changed a record on the page (only set for secondary indexes) | 00 00 00 00 00 00 00 00 |
| PAGE_LEVEL | 2 | level within the index (0 for a leaf page) | 00 00 |
| PAGE_INDEX_ID | 8 | identifier of the index the page belongs to | 00 00 00 00 00 00 00 16 |
| PAGE_BTR | 10 | "file segment header for the leaf pages in a B-tree" (this is irrelevant here) | 00 00 00 06 00 00 00 02 00 F2 |
| PAGE_LEVEL | 10 | "file segment header for the non-leaf pages in a B-tree" (this is irrelevant here) | 00 00 00 06 00 00 00 02 00 32 |
0xc000 + 01 ED=0xC1ED地址后面的都是空闲的

0xc000 + 01 C5=0xC1C5最后一条记录
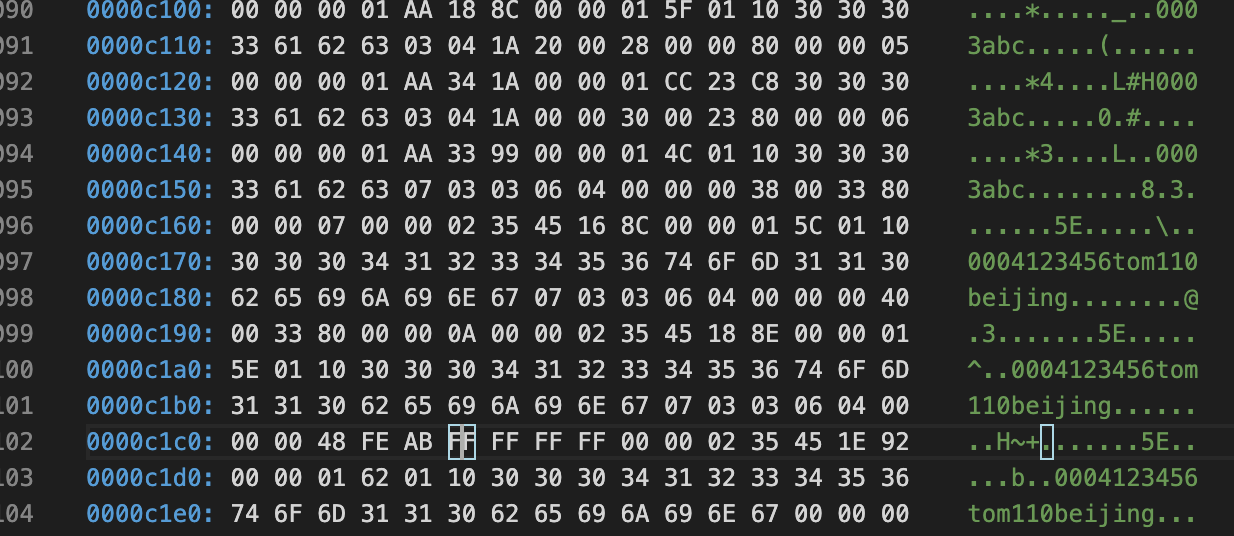
分析Infimum + Supremum Record (26字节-两个虚拟行记录)
infimum: n. 下确界; supremum: n. 上确界;
Infimum和Suprenum Record用来限定记录的边界,Infimum是比页中任何主键值都要小的值,Suprenum是指比任何页中可能大值还要大的值,这两个值在页创建时被建立,并且在任何情况下都不会被删除。Infimum和Suprenum与行记录组成单链表结构,查询记录时,从Infimum开始查找,如果找不到结果会直到查到最后的Suprenum为止,然后通过Page Header中的FIL_PAGE_NEXT指针跳转到下一个page继续从Infimum开始逐个查找
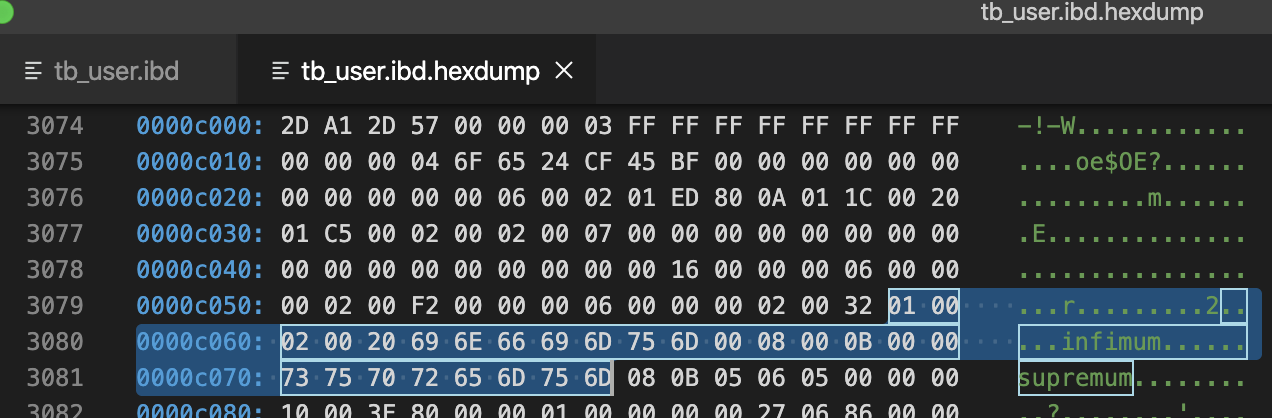
#Infimum伪行记录
01 00 02 00 20/*recorder header*/
69 6E 66 69 6D 75 6D 00/*只有一个列的伪行记录,记录内容就是Infimum(多了一个0x00字节)
*/
#Supremum伪行记录
08 00 0B 00 00/*recorder header*/
73 75 70 72 65 6D 75 6D/*只有一个列的伪行记录,记录内容就是Supremum*/
infimum行记录的recorder header部分,最后2个字节位00 20表示下一个记录的位置的偏移量
User Record(表中的数据记录)
用户所有插入的记录都存放在这里,默认情况下记录跟记录之间没有间隙,但是如果重用了已删除记录的空间,就会导致空间碎片。每个记录都有指向下一个记录的指针,但是没有指向上一个记录的指针。记录按照主键顺序排序:即用户可以从数据页最小记录开始遍历,直到最大的记录,这包括了所有正常的记录和所有被delete-marked记录,但是不会访问到被删除的记录(PAGE_FREE)
COMPACT行记录格式
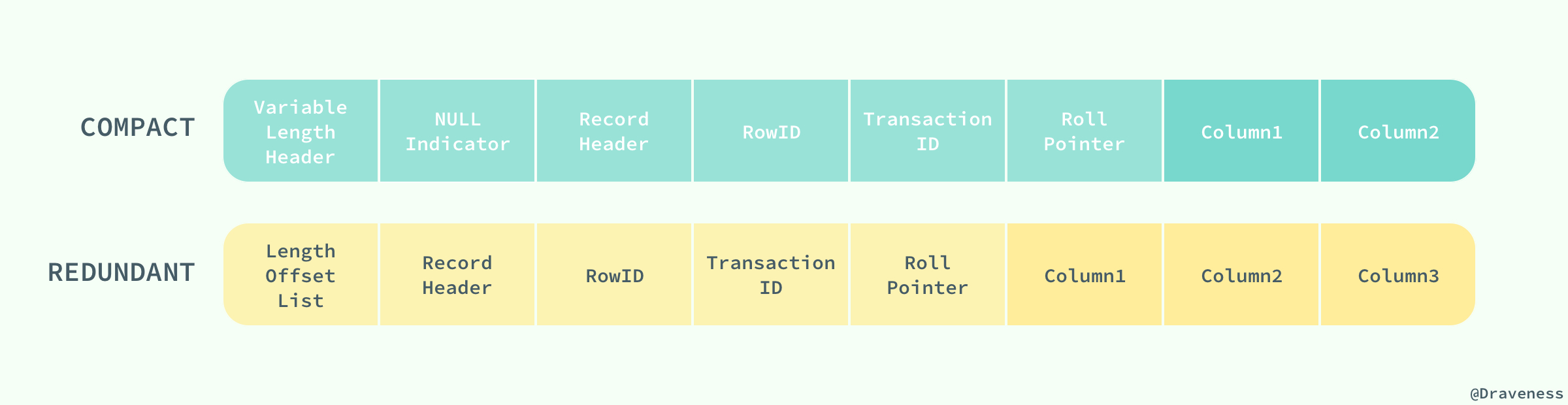
行格式的首部是一个非NULL变长字段长度列表,而且是按照列的顺序逆序放置的。当列的长度小于255字节,用1字节表示,若大于255个字节,用2个字节表示,变长字段的长度最大不可以超过2个字节(这也很好地解释了为什么MySQL中varchar的最大长度为65535,因为2个字节为16位,即
pow(2,16)-1=65536)。第二个部分是NULL标志位,该位指示了该行数据中是否有NULL值,1个字节表示;该部分所占的字节应该为bytes;接下去的部分是为记录头信息(record header),固定占用5个字节(40位),每位的含义如下预留位1 1(bit位) 没有使用
- 预留位2 1 没有使用
- delete_mask 1 标记该记录是否被删除
- min_rec_mask 1 标记该记录是否为B+树的非叶子节点中的最小记录
- n_owned 4 表示当前槽管理的记录数
- heap_no 13 表示当前记录在记录堆的位置信息
- record_type 3 表示当前记录的类型,0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3表示最大记录
- next_record 16 表示下一条记录的相对位置
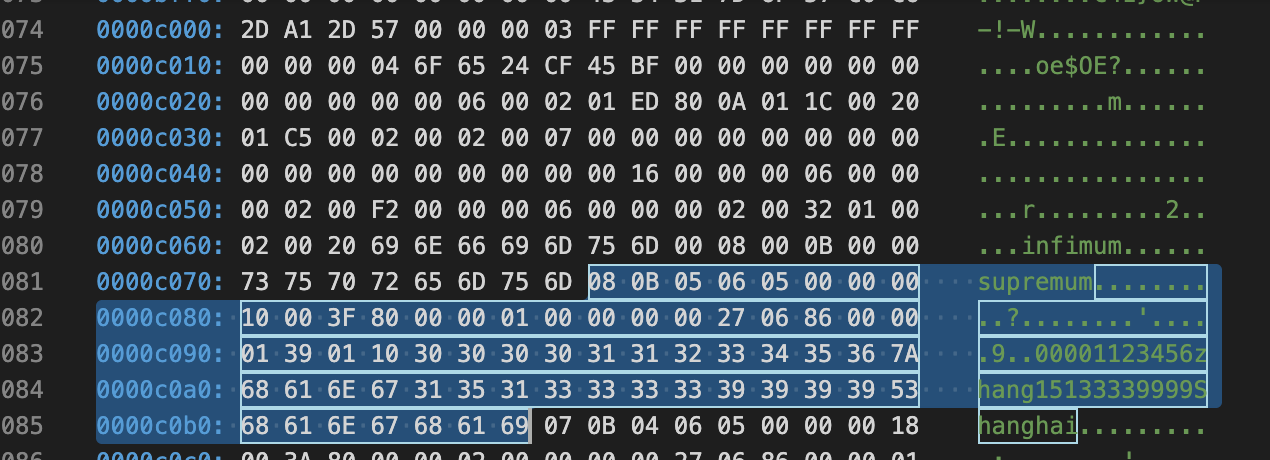
0000c070: 73 75 70 72 65 6D 75 6D 08 0B 05 06 05 00 00 00 supremum........
0000c080: 10 00 3F 80 00 00 01 00 00 00 00 27 06 86 00 00 ..?........'....
0000c090: 01 39 01 10 30 30 30 30 31 31 32 33 34 35 36 7A .9..00001123456z
0000c0a0: 68 61 6E 67 31 35 31 33 33 33 33 39 39 39 39 53 hang15133339999S
0000c0b0: 68 61 6E 67 68 61 69 07 0B 04 06 05 00 00 00 18 hanghai.........
08 0B 05 06 05: 8(address字段) 11(phone字段) 5(name字段) 6(password字段) 5(userID字段),一个逆序的方式表示可变长字段列表
00 : Null值列表
00 00 10 00 3F:记录头信息 5个字节,40bit
0000 0000 0000 0000 00001 0000 0000 0000 0011 1111
80 00 00 01:自增主键(有符号的int类型),1
00 00 00 00 27 06:隐藏列 DB_TRX_ID
86 00 00 01 39 01 10:隐藏列 DB_ROLL_PTR
30 30 30 30 31 : 00001
31 32 33 34 35 36 : 123456
7A 68 61 6E 67 : zhang
31 35 31 33 33 33 33 39 39 39 39 : 15133339999
53 68 61 6E 67 68 61 69 : beijing
File Tailer(最后8字节)
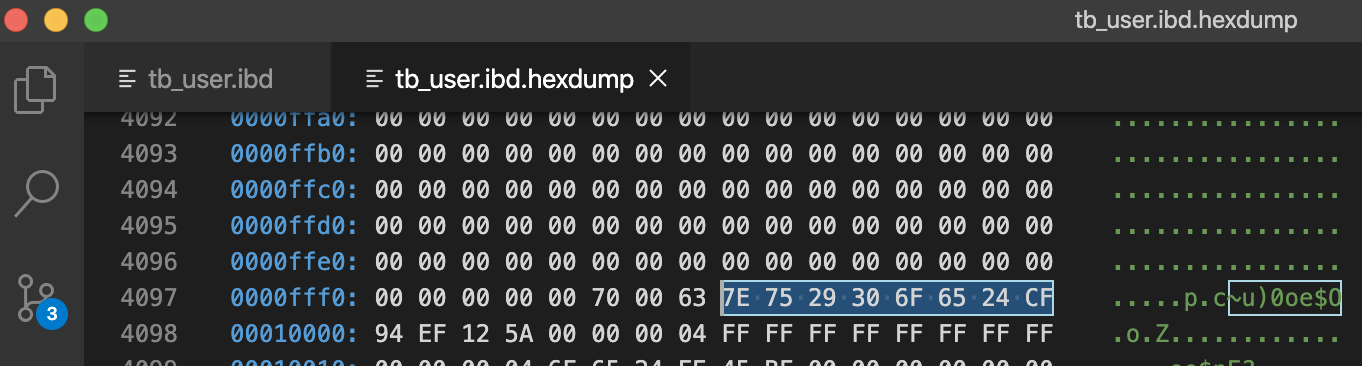
7E 75 29 30 6F 65 24 CF
注意到File Header该页最后被修改的LSN:00 00 00 04 6F 65 24 CF,可以看到后4个字节和File Tailer的后4个字节相同
附:二进制文件查看小技巧
- 使用python可以方便的进行二进制相关的转换
- hex(16) # 10进制转16进制
- oct(8) # 10进制转8进制
- bin(8) # 10进制转2进制
>>> hex(6 * 16 * 1024)
'0x18000'
>>> hex(3 * 16 * 1024)
'0xc000'
>>>
- vscode可以安装
hexdump for VSCode插件
页分裂/页合并
innodb-page-merging-and-page-splitting
InnoDB不是按行的来操作的,它可操作的最小粒度是页,页加载进内存后才会通过扫描页来获取行/记录,curd操作会产生页合并,页分裂操作。
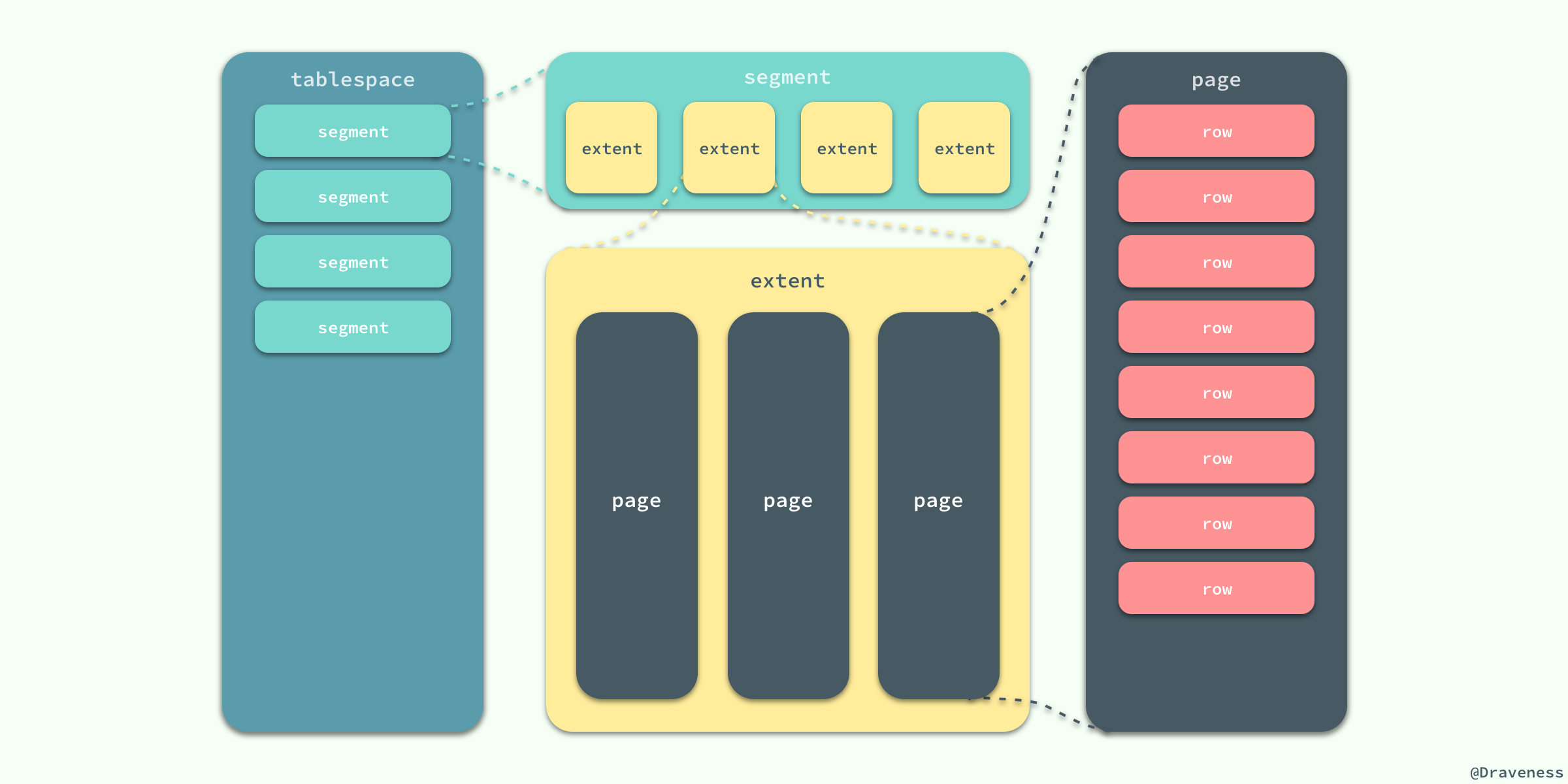
innodb数据的存储
在 InnoDB 存储引擎中,所有的数据都被逻辑地存放在表空间中,表空间(tablespace)是存储引擎中最高的存储逻辑单位,在表空间的下面又包括段(segment)、区(extent)、页(page), 页中存放实际的数据记录行
MySQL 使用 InnoDB 存储表时,会将表的定义和数据相关记录、索引等信息分开存储,其中前者存储在.frm文件中,后者存储在.ibd文件中(ibd文件既存储了数据也存储了索引)
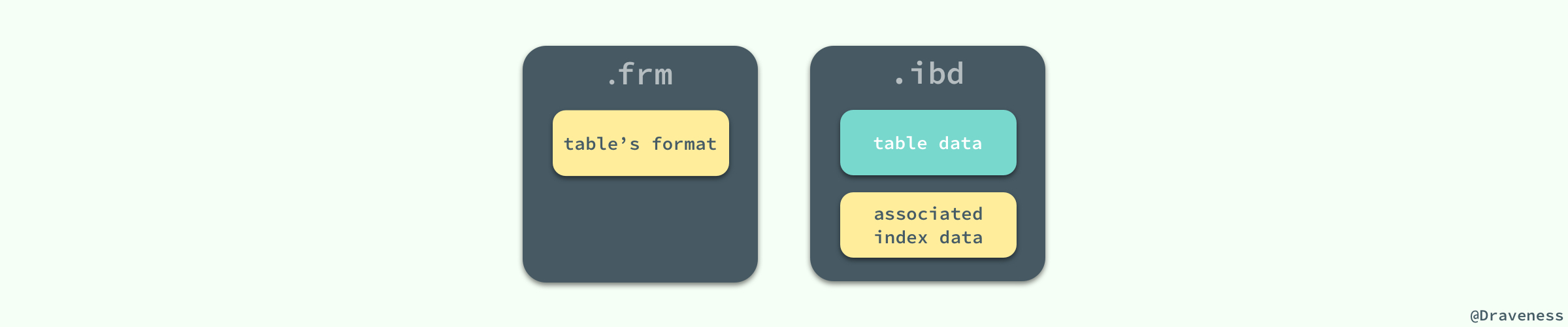
在创建表时,会在磁盘上的 datadir 文件夹中生成一个 .frm 的文件,这个文件中包含了表结构相关的信息
页合并
删除记录时会设置record的flaged标记为删除,当一页中删除记录超过MERGE_THRESHOLD(默认页体积的50%)时,InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用。例如:合并操作使得页#5保留它之前的数据,并且容纳来自页#6的数据。页#6变成一个空页,可以接纳新数据。
页分裂
页可能填充至100%,在页填满了之后,下一页会继续接管新的记录。但如果下一页也没有足够空间去容纳新(或更新)的记录,那么就必须创建新的页了,如下
- 创建新页
- 判断当前页(页#10)可以从哪里进行分裂(记录行层面)
- 移动记录行
- 重新定义页之间的关系
#9 #10 #11 #12 #13 ...
#8 #10 #14 #11 #12 #13 ...
如上,页#10没有足够空间去容纳新记录,页#11也同样满了, #10要分列为两列, 且页的前后指针关系要发生改变
Myql索引
MySql默认索引(B+Tree)
mysql> show variables like '%storage_engine%';
ERROR 2006 (HY000): MySQL server has gone away
No connection. Trying to reconnect...
Connection id: 112
Current database: test
+----------------------------+--------+
| Variable_name | Value |
+----------------------------+--------+
| default_storage_engine | InnoDB |
| default_tmp_storage_engine | InnoDB |
| storage_engine | InnoDB |
+----------------------------+--------+
3 rows in set (0.06 sec)
mysql>
为什么要用B+ Tree而不是B Tree?
1行记录假如有1KB;如果用B Tree:其非叶子节点是要存储数据的,显然存储有限,为了存储大量数据,不得不提高树的高度,这样使用B Tree就会导致磁盘IO次数增多;所以有B+ Tree,降低树高度,减少磁盘IO
MySql中B+树索引可以分为聚集索引和非聚集索引
聚集索引(clustered index)
索引中键值的逻辑顺序决定了表中相应行的物理顺序(即索引中的数据物理存放地址和索引的顺序是一致的),可以这么理解:只要是索引是连续的,那么数据在存储介质上的存储位置也是连续的。
聚集索引就像我们根据拼音的顺序查字典一样,可以大大的提高效率。在经常搜索一定范围的值时,通过索引找到第一条数据,根据物理地址连续存储的特点,然后检索相邻的数据,直到到达条件截止项即可。
聚集索引:叶子节点包含了完整的数据记录
Cluster index is a type of index which sorts the data rows in the table on their key values. In the Database, there is only one clustered index per table.
A clustered index defines the order in which data is stored in the table which can be sorted in only one way. So, there can be an only a single clustered index for every table. In an RDBMS, usually, the primary key allows you to create a clustered index based on that specific column.
非聚集索引
索引的逻辑顺序与磁盘上的物理存储顺序不同。非聚集索引的键值在逻辑上也是连续的,但是表中的数据在存储介质上的物理顺序是不一致的,即记录的逻辑顺序和实际存储的物理顺序没有任何联系;索引的记录节点有一个数据指针指向真正的数据存储位置。
A Non-clustered index stores the data at one location and indices at another location. The index contains pointers to the location of that data. A single table can have many non-clustered indexes as an index in the non-clustered index is stored in different places.
For example, a book can have more than one index, one at the beginning which displays the contents of a book unit wise while the second index shows the index of terms in alphabetical order.
A non-clustering index is defined in the non-ordering field of the table. This type of indexing method helps you to improve the performance of queries that use keys which are not assigned as a primary key. A non-clustered index allows you to add a unique key for a table.
聚集/非聚集对比和注意点
Mysql中关于聚集索引的说明
* 如果一个主键被定义了,那么这个主键就是作为聚集索引
* 如果没有主键被定义,那么该表的第一个唯一非空索引会被作为聚集索引
* 如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,该列的值会随着数据的插入进行自增
聚集索引的特点
* 聚集索引表记录的排列顺序和索引的排列顺序保持一致,所以查询效率相当快。只要找到第一个索引记录的值,其余的连续性的记录也一定是连续存放的
* 聚集索引的缺点就是修改,删除等操作会比较慢,因为它需要保持表中记录和索引的顺序一致,在插入新记录的时候就会对数据也重新做一次排序,可能产生页分裂/创建操作
* InnoDB表数据本身就是一个按`B+Tree`组织的一个索引结构文件,叶节点包含了完整的数据记录(.ibd文件);MyIsam数据和索引文件是分开的(.MYD文件,.MYI文件)
- myisam
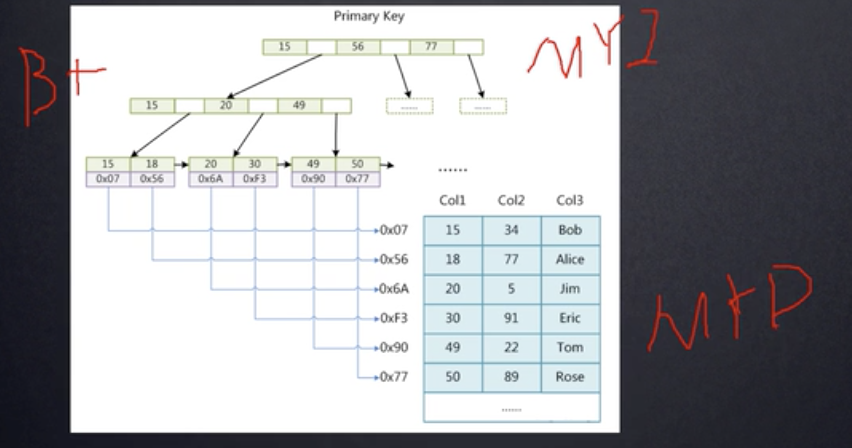
- innodb
为什么InnoDB要有主键?并且推荐使用整型自增主键?
为什么InnoDB要有主键?(InnoDB设计如此)
- 如果一个主键被定义了,那么这个主键就是作为聚集索引
- 如果没有主键被定义,那么该表的第一个唯一非空索引会被作为聚集索引
- 如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,该列的值会随着数据的插入进行自增
推荐使用整型?
- B+Tree搜索进行比较操作时,显然整型比字符串比较快(原因1);整型占用空间小(原因2)
推荐使用自增?
补充:hash索引,直接定位到记录的磁盘地址(等值查找);但是区间查找用hash行不同,所以hash索引在数据库中用的少
自增是页不断的创建新增,尾部数据增加,调整小;如果非自增,涉及到页分裂/创建,B+Tree调整大
索引类型
主键索引和非主键索引的区别?
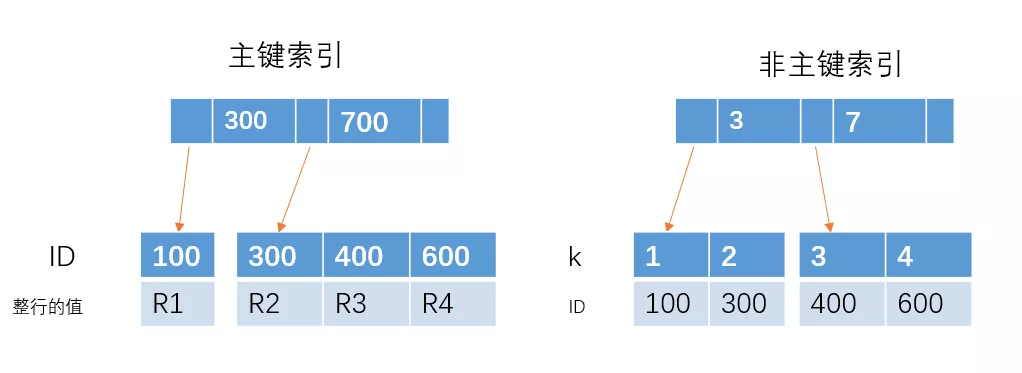
- 非主键索引的叶子节点存放的是主键的值
- 主键索引的叶子节点存放的是整行数据
- 其中非主键索引也被称为二级索引,而主键索引也被称为聚簇索引。
eg:
- 如果查询语句是
select * from table where ID = 100,即主键查询的方式,则只需要搜索 ID 这棵 B+树。 - 如果查询语句是
select * from table where k = 1,即非主键的查询方式,则先搜索k索引树,得到ID=100,再到ID索引树搜索一次,这个过程也被称为回表。
主键和唯一索引有什么区别?
- 主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。
- 主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。
- 唯一性索引列允许空值,而主键列不允许为空值。
- 主键列在创建时,已经默认为空值 + 唯一索引了。
- 主键可以被其它表引用为外键,而唯一索引不能。
- 一个表最多只能创建一个主键,但可以创建多个唯一索引。
- 主键更适合那些不容易更改的唯一标识,如自动递增列、身份证号等。
联合索引
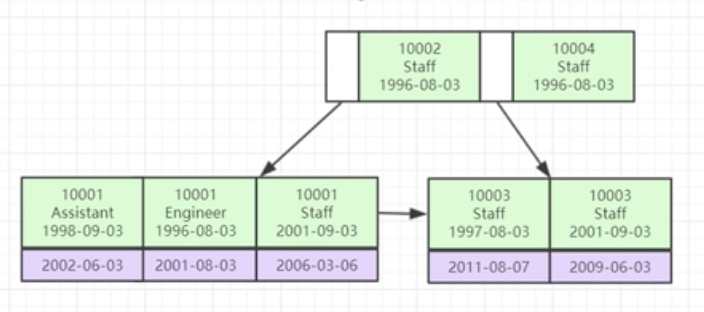
仍然是B+Tree(联合索引也是一个B+树,在索引比较的时候会按照次序的比较,否则无法比较,也就不能走联合索引), 索引中包含多个字段,按照联合索引的先后顺序;如a,b,c联合索引,则a; a,b; a,b,c;可以走索引,其它则不能
eg:对id列.name列.age列建立了一个联合索引 id_name_age_index,实际上相当于建立了三个索引(id)(id_name)(id_name_age)
联合索引为什么是最左前缀匹配
数据结构底层决定(严格的按照第一个,第二个,第三个字段一个一个匹配),不符合最左匹配则需要全局扫描了;且最左匹配原则遇到范围查询就停止匹配
eg:
create table test(
a int,
b int,
c int,
KEY a(a,b,c)
);
mysql> show index from test;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| test | 1 | a | 1 | a | A | 0 | NULL | NULL | YES | BTREE | | |
| test | 1 | a | 2 | b | A | 0 | NULL | NULL | YES | BTREE | | |
| test | 1 | a | 3 | c | A | 0 | NULL | NULL | YES | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.01 sec)
如下各种语句索引的使用情况:
where a = 3 用到索引 a
where a = 3 and b = 3 用到索引 a,b
where a = 3 and b = 4 and c = 5 用到索引 a,b,c
where b = 3 或者 where b = 3 and c = 4 或者 where c = 4 索引失效
where a = 3 and c = 5 用到索引 a
where a = 3 and b > 4 and c = 5 用到索引a和b(b的范围导致未用到c)
where a = 3 and b like 'kk%' and c = 4 用到索引a,b,c
where a = 3 and b like '%kk' and c = 4 只用索引a
where a = 3 and b like '%kk%' and c = 4 只用到索引a
where a = 3 and b like 'k%kk%' and c = 4 用到a,b,c
where a > 1 and a < 3 and b > 1 用到索引a,没有用到索引b
联合索引优化例子
select * from table where a = xxx and b = xxx;占60%
select b from table where b = xxx; 占39%;
其它占1%;怎么优化?
解答:将第一条sql语句改为select * from table where b = xxx and a = xxx,然后建立ba的联合索引,因为ba的联合索引可以支持b和ba这两种组合的查找,这样就减少了开销
Mysql中的like是否使用索引
通过like '%XX%'查询的时候会造成索引失效,一般采用like 'XX%'右边匹配的方式来索引。但是这样一定会使用索引吗?否
MySql索引概述和分类
Most MySQL indexes (PRIMARY KEY, UNIQUE, INDEX, and FULLTEXT) are stored in B-trees. Exceptions: Indexes on spatial data types use R-trees; MEMORY tables also support hash indexes; InnoDB uses inverted lists for FULLTEXT indexes.
- 主键索引:又叫聚簇索引,是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值
- 普通索引:也叫非主键索引,回表,借助主键索引
- 唯一索引:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一;唯一索引可以保证数据记录的唯一性。事实上,在许多场合,人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。
- 全文索引:倒排索引
https://dev.mysql.com/doc/refman/5.7/en/mysql-indexes.html
Indexes are used to find rows with specific column values quickly. Without an index, MySQL must begin with the first row and then read through the entire table to find the relevant rows. The larger the table, the more this costs. If the table has an index for the columns in question, MySQL can quickly determine the position to seek to in the middle of the data file without having to look at all the data. This is much faster than reading every row sequentially.(索引适用于快速查找某些行,而不需要让引擎去做全表扫描.当然这些做是有条件的,索引的创建和更新是需要资源的(CPU IO 内存 磁盘空间).所以索引通过牺牲插入和更新的效率来大幅度提高读的效率.)
Most MySQL indexes (PRIMARY KEY, UNIQUE, INDEX, and FULLTEXT) are stored in B-trees. Exceptions: Indexes on spatial data types use R-trees; MEMORY tables also support hash indexes; InnoDB uses inverted lists for FULLTEXT indexes.
MySQL uses indexes for these operations:
To find the rows matching a WHERE clause quickly.
To eliminate rows from consideration. If there is a choice between multiple indexes, MySQL normally uses the index that finds the smallest number of rows (the most selective index).
If the table has a multiple-column index, any leftmost prefix of the index can be used by the optimizer to look up rows. For example, if you have a three-column index on (col1, col2, col3), you have indexed search capabilities on (col1), (col1, col2), and (col1, col2, col3).
To retrieve rows from other tables when performing joins. MySQL can use indexes on columns more efficiently if they are declared as the same type and size. In this context, VARCHAR and CHAR are considered the same if they are declared as the same size. For example, VARCHAR(10) and CHAR(10) are the same size, but VARCHAR(10) and CHAR(15) are not.
To find the MIN() or MAX() value for a specific indexed column key_col. This is optimized by a preprocessor that checks whether you are using WHERE key_part_N = constant on all key parts that occur before key_col in the index. In this case, MySQL does a single key lookup for each MIN() or MAX() expression and replaces it with a constant. If all expressions are replaced with constants, the query returns at once.
To sort or group a table if the sorting or grouping is done on a leftmost prefix of a usable index (for example, ORDER BY key_part1, key_part2). If all key parts are followed by DESC, the key is read in reverse order.
In some cases, a query can be optimized to retrieve values without consulting the data rows. (An index that provides all the necessary results for a query is called a covering index.) If a query uses from a table only columns that are included in some index, the selected values can be retrieved from the index tree for greater speed
最后:Indexes are less important for queries on small tables, or big tables where report queries process most or all of the rows. When a query needs to access most of the rows, reading sequentially is faster than working through an index. Sequential reads minimize disk seeks, even if not all the rows are needed for the query.
非主键索引(回表:bookmark lookup)
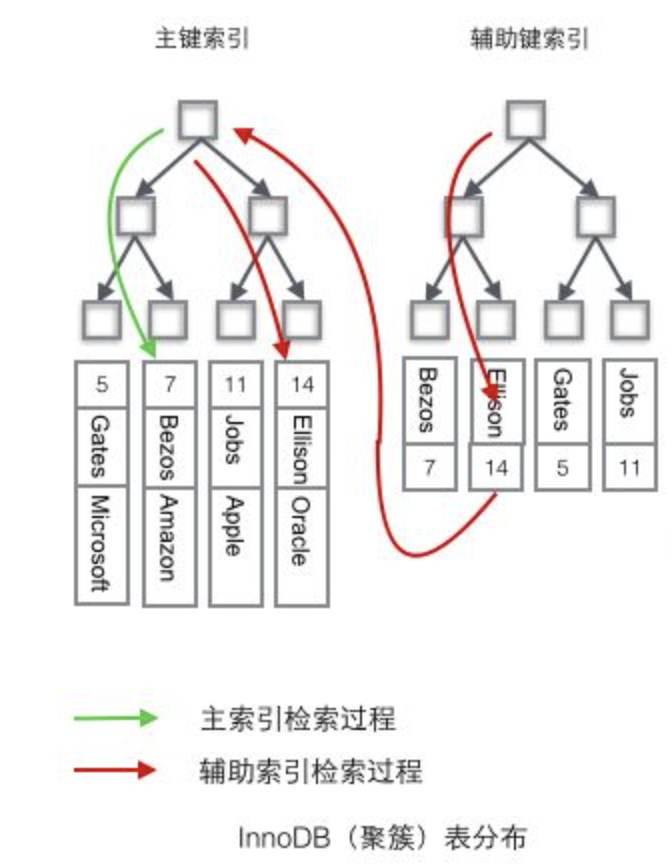
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树中再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。(重点在于通过其它键需要建立辅助索引)
聚集索引的优势:
由于行数据和叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中,再次访问的时候,会在内存中完成访问,不必访问磁盘。这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快
辅助索引使用主键作为"指针"而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响
聚簇索引适合用在排序的场合,非聚簇索引不适合
取出一定范围数据的时候,使用用聚簇索引
二级索引需要两次索引查找,而不是一次才能取到数据,因为存储引擎第一次需要通过二级索引找到索引的叶子节点,从而找到数据的主键,然后在聚簇索引中用主键再次查找索引,再找到数据
可以把相关数据保存在一起。例如实现电子邮箱时,可以根据用户 ID 来聚集数据,这样只需要从磁盘读取少数的数据页就能获取某个用户的全部邮件。如果没有使用聚簇索引,则每封邮件都可能导致一次磁盘 I/O
覆盖索引
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为"覆盖索引"。即只需扫描索引而无须回表。
create table user_test (
id bigint(20) not null auto_increment ,
name varchar(255) not null,
password varchar(255) ,
primary key (id),
index index_name (name) using btree)
engine=innodb default character set=utf8;
如下两个查询
语句A: select id from t_user where name = '张三'
语句B: select password from t_user where name = '张三' -- 需要回表
当sql语句的所求查询字段(select列)和查询条件字段(where子句)全都包含在一个索引中(联合索引),可以直接使用索引查询而不需要回表。可以建立(name,password)的联合索引,这样,查询的时候就不需要再去回表操作了,可以提高查询效率。
那么不用主键索引就一定需要回表吗?不一定:如果查询的列本身就存在于索引中,那么即使使用二级索引,一样也是不需要回表的。
索引下推(index condition pushdown)
索引下推(index condition pushdown )简称ICP,在Mysql5.6的版本上推出,它能减少回表查询次数,提高查询效率。
在不使用ICP的情况下,在使用非主键索引(又叫普通索引或者二级索引)进行查询时,存储引擎通过索引检索到数据,然后返回给MySQL服务器,服务器然后判断数据是否符合条件 。
在使用ICP的情况下,如果存在某些被索引的列的判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器 。
索引条件下推优化可以减少存储引擎查询基础表的次数,也可以减少MySQL服务器从存储引擎接收数据的次数。
例子:
使用一张用户表tuser,表里创建联合索引(name, age)
select * from tuser where name like '张%' and age=10;按照最左匹配原则,这个语句在搜索索引树的时候,只能用张匹配,假设有2条记录符合,但是age=10的只有一条记录;
没有使用ICP,假设主键id(1、4),逐一进行回表扫描,去聚簇索引找到完整的行记录,server层再对数据根据age=10进行筛选。
使用ICP,存储引擎根据(name,age)联合索引,找到,由于联合索引中包含列,所以存储引擎直接再联合索引里按照age=10过滤;按照过滤后的数据再一一进行回表扫描。这样只回表了一次。
查看和设置索引下推
select @@optimizer_switch
set ="index_condition_pushdown=off";
set ="index_condition_pushdown=on";
InnoDb锁
Shared locks(读锁) 和 Exclusive locks(写锁)
InnoDB implements standard row-level locking where there are two types of locks, shared (S) locks and exclusive (X) locks.
- A shared (S) lock permits the transaction that holds the lock to read a row.
- An exclusive (X) lock permits the transaction that holds the lock to update or delete a row.
Exclusive locks
Exclusive locks protect updates to file resources, both recoverable and non-recoverable. They can be owned by only one transaction at a time. Any transaction that requires an exclusive lock must wait if another task currently owns an exclusive lock or a shared lock against the requested resource.
独占锁保护文件资源(包括可恢复和不可恢复的文件资源)的更新。它们一次只能由一个事务拥有。如果另一个任务当前拥有对所请求资源的独占锁或共享锁,则任何需要对该资源申请独占锁的事务都必须等待。
Shared locks
Shared locks support read integrity. They ensure that a record is not in the process of being updated during a read-only request. Shared locks can also be used to prevent updates of a record between the time that a record is read and the next syncpoint.
共享锁支持读完整性。它们确保在只读请求期间不会更新记录。共享锁还可用于防止在读取记录和下一个同步点之间进行更新操作。
A shared lock on a resource can be owned by several tasks at the same time. However, although several tasks can own shared locks, there are some circumstances in which tasks can be forced to wait for a lock:
资源上的共享锁可以同时由多个任务拥有。 但是,尽管有几个任务可以拥有共享锁,但在某些情况下可以强制任务等待锁:
- A request for a shared lock must wait if another task currently owns an exclusive lock on the resource.
- A request for an exclusive lock must wait if other tasks currently own shared locks on this resource.
- A new request for a shared lock must wait if another task is waiting for an exclusive lock on a resource that already has a shared lock.
即:
- 如果另一个任务当前拥有资源上的独占锁,则对共享锁的请求必须等待
- 如果其他任务当前拥有此资源上的共享锁,则必须等待对独占锁的请求
- 如果另一个任务正在等待已经具有共享锁的资源的独占锁,则对共享锁的新请求必须

Intention Locks(意向锁)
InnoDB supports multiple granularity locking(多粒度锁) which permits coexistence of row locks and table locks.
Intention locks are table-level locks that indicate which type of lock (shared or exclusive) a transaction requires later for a row in a table. There are two types of intention locks:
An intention shared lock (IS) indicates that a transaction intends to set a shared lock on individual rows in a table. 事务T尝试在表t的某些行记录上设置S锁
An intention exclusive lock (IX) indicates that a transaction intends to set an exclusive lock on individual rows in a table. 事务T尝试在表t的某些行记录上设置X锁
锁使用规则:
| - | X | IX | S | IS |
|---|---|---|---|---|
| X | Conflict | Conflict | Conflict | Conflict |
| IX | Conflict | Compatible | Conflict | Compatible |
| S | Conflict | Conflict | Compatible | Compatible |
| IS | Conflict | Compatible | Compatible | Compatible |
为什么要有意向锁?
表级别锁,加锁效率提高;申请意向锁的动作是数据库完成的,就是说,事务A申请一行的行锁的时候,数据库会自动先开始申请表的意向锁,不需要我们程序员使用代码来申请
考虑场景:A事务行锁(锁住一行,只能读,不能写);B事务表锁,如果能加锁成功,那么理论上可以操作每一行,则与A事务有冲突了,B事务必须等待A事务结束再进行操作,那么B事务怎么判断冲突?
- 判断表是否已被其他事务用表锁锁表
- 判断表中的每一行是否已被行锁锁住。(遍历每一行判断效率太低)
事务A必须先申请表的意向共享锁,成功后再申请一行的行锁。事务B发现表上有意向共享锁,说明表中有些行被共享行锁锁住了;因此,事务B申请表的写锁会被阻塞。
Record Locks
A record lock is a lock on an index record. For example, SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE; prevents any other transaction from inserting, updating, or deleting rows where the value of t.c1 is 10.
Record locks always lock index records, even if a table is defined with no indexes. For such cases, InnoDB creates a hidden clustered index and uses this index for record locking.
单个索引行记录的锁。
Gap Locks
A gap lock is a lock on a gap between index records, or a lock on the gap before the first or after the last index record. For example, SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20 FOR UPDATE; prevents other transactions from inserting a value of 15 into column t.c1, whether or not there was already any such value in the column, because the gaps between all existing values in the range are locked.
A gap might span a single index value, multiple index values, or even be empty.
Gap locks are part of the tradeoff between performance and concurrency, and are used in some transaction isolation levels and not others.
间隙锁,锁定一个范围,但不包括记录本身。GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况。
Next-Key Locks
A next-key lock is a combination of a record lock on the index record and a gap lock on the gap before the index record.
InnoDB performs row-level locking in such a way that when it searches or scans a table index, it sets shared or exclusive locks on the index records it encounters. Thus, the row-level locks are actually index-record locks. A next-key lock on an index record also affects the “gap” before that index record. That is, a next-key lock is an index-record lock plus a gap lock on the gap preceding the index record. If one session has a shared or exclusive lock on record R in an index, another session cannot insert a new index record in the gap immediately before R in the index order.
锁定一个范围,并且锁定记录本身。对于行的查询,都是采用该方法,主要目的是解决幻读的问题。
例如:
root@localhost : test 10:56:15>select * from t;
+------+
| a |
+------+
| 1 |
| 3 |
| 5 |
| 8 |
| 11 |
+------+
5 rows in set (0.00 sec)
root@localhost : test 10:56:29>select * from t where a = 8 for update;
+------+
| a |
+------+
| 8 |
+------+
1 row in set (0.00 sec)
该SQL语句锁定的范围是(5,8],下个下个键值范围是(8,11],所以插入5~11之间的值的时候都会被锁定,要求等待。即:插入5,6,7,8,9,10会被锁住。插入非这个范围内的值都正常。
Insert Intention Locks(插入意向锁)
An insert intention lock is a type of gap lock set by INSERT operations prior to row insertion. This lock signals the intent to insert in such a way that multiple transactions inserting into the same index gap need not wait for each other if they are not inserting at the same position within the gap. Suppose that there are index records with values of 4 and 7. Separate transactions that attempt to insert values of 5 and 6, respectively, each lock the gap between 4 and 7 with insert intention locks prior to obtaining the exclusive lock on the inserted row, but do not block each other because the rows are nonconflicting.
Insert Intention Locks意为插入意向锁,插入意向锁是Innodb gap锁的一种类型,这种锁表示要以这样一种方式插入:如果多个事务插入到相同的索引间隙中,如果它们不在间隙中的相同位置插入,则无需等待其他事务。比如说有索引记录4和7,有两个事务想要分别插入5,6,在获取插入行上的独占锁之前,每个锁都使用插入意图锁锁定4和7之间的间隙,但是不要互相阻塞,因为行是不冲突的,意向锁的涉及是为了插入的正确和高效。
AUTO-INC Locks
Predicate Locks for Spatial Indexes
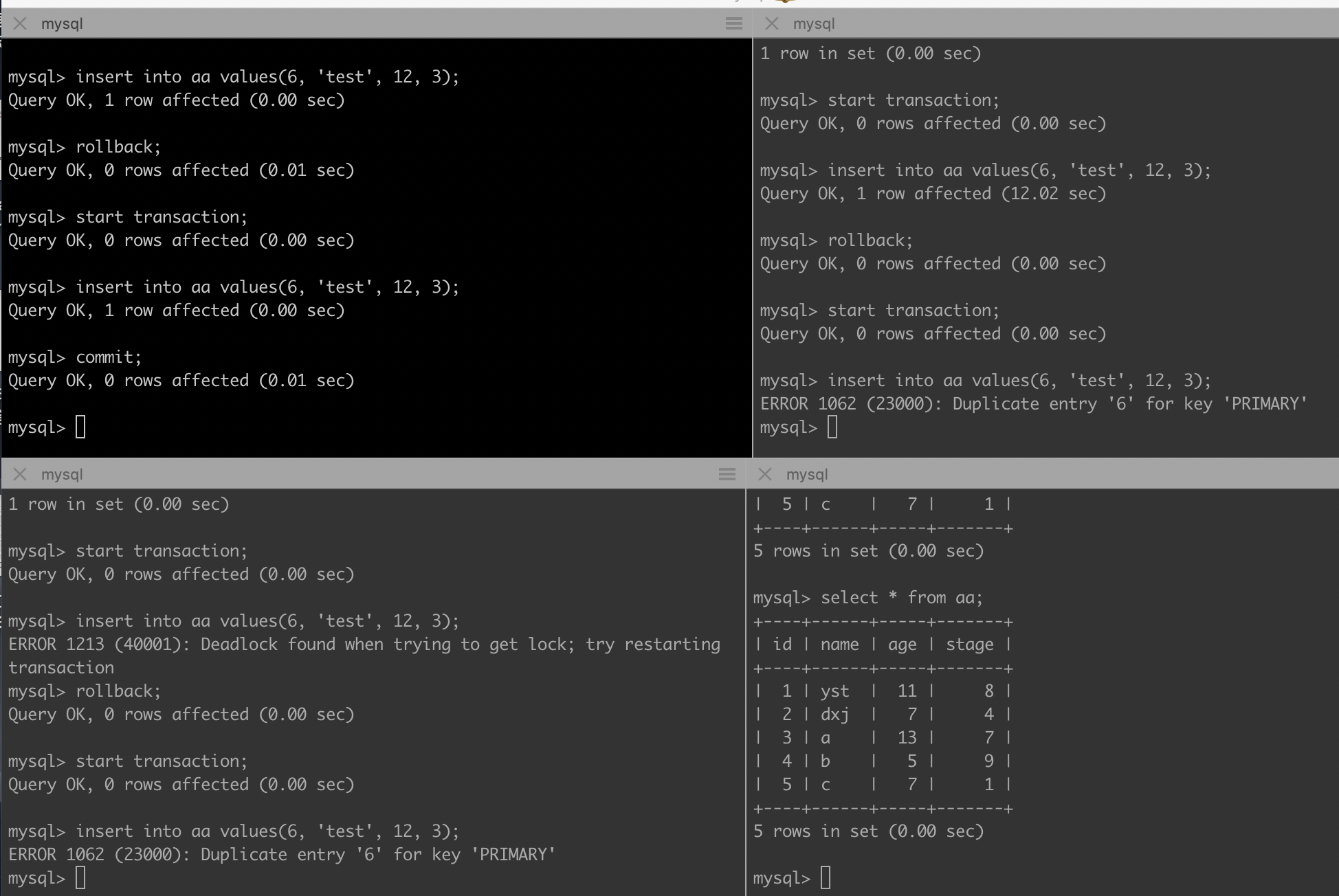
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
三个事务都插入相同数据,其中第一个事务进行了回滚,第三个事务报错

在第一个事务回滚之前,查看事务锁情况
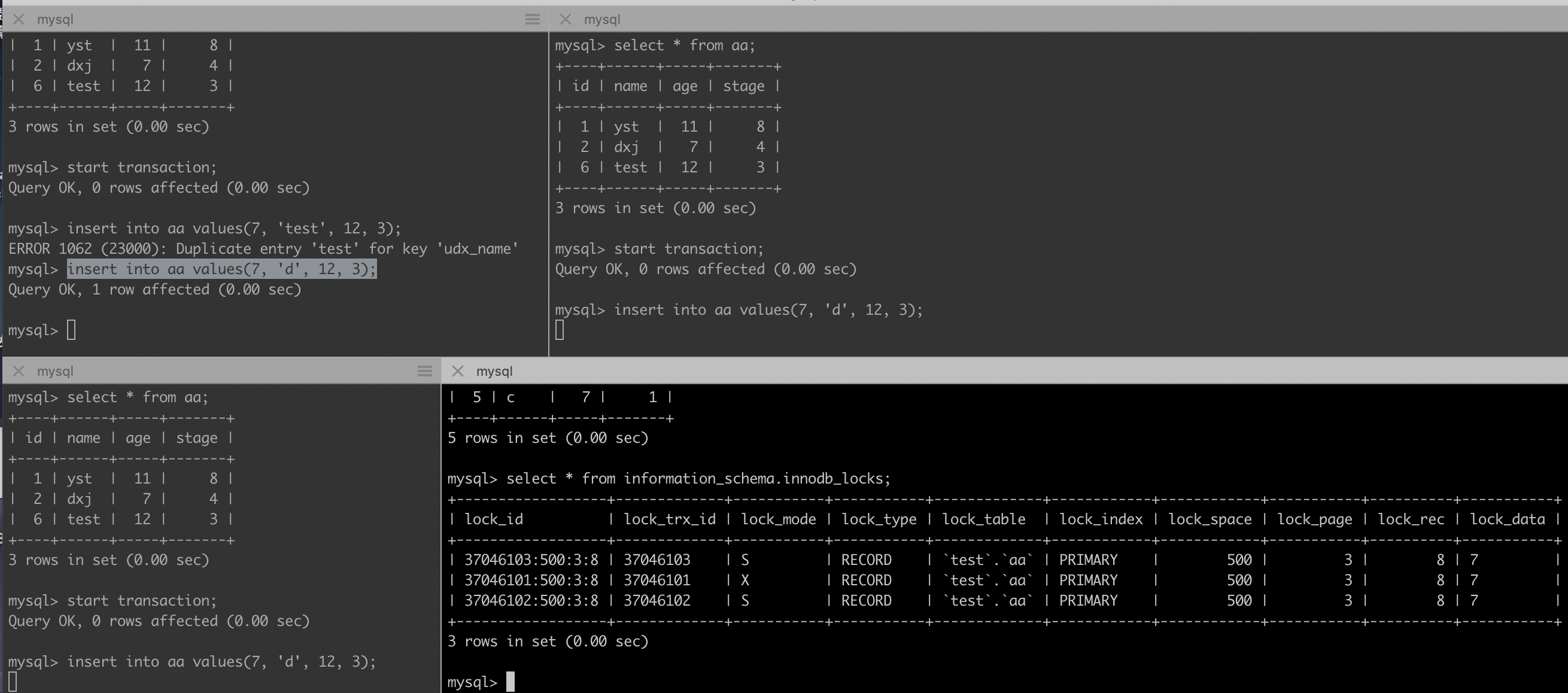
- 事务1获得行记录上的排它锁(LOCK_X | LOCK_REC_NOT_GAP)
- 紧接着事务T2、T3也开始插入记录,请求排它插入意向锁(LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION);但由于发生重复唯一键冲突,各自请求的排它记录锁(LOCK_X | LOCK_REC_NOT_GAP)转成共享记录锁(LOCK_S | LOCK_REC_NOT_GAP)。
T1回滚会释放其获取到到排它锁,T2,T3都要请求排它锁,但是由于X锁与S锁互斥,T2与T3都等待对方释放S锁,于是便产生了死锁
ERROR 1062 (23000): Duplicate entry '6' for key 'PRIMARY'
乐观/悲观锁(select for update)
乐观锁认为一般情况下数据不会造成冲突,所以在数据进行提交更新时才会对数据的冲突与否进行检测。如果没有冲突那就OK;如果出现冲突了,则返回错误信息并让用户决定如何去做。一般就是:1. CAS; 2. 版本控制
悲观锁,正如其名,它指的是对数据被外界(包括当前系统的其它事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排它性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
使用select … for update会把数据给锁住,不过我们需要注意一些锁的级别,MySQL InnoDB默认Row-Level Lock,且只有「明确」地指定主键,MySQL 才会执行Row lock (只锁住被选取的数据) ;否则 MySQL 将会执行Table Lock(将整个数据表给锁住)
| - | 悲观锁 | 乐观锁 |
|---|---|---|
| 概念 | 查询时直接锁住记录使得其它事务不能查询,更不能更新 | 提交更新时检查版本或者时间戳是否符合 |
| 语法 | select ... for update | 使用 version 或者 timestamp 进行比较 |
| 实现者 | 数据库本身 | 开发者 |
| 适用场景 | 并发量大 | 并发量小 |
| 类比Java | synchronized关键字 | CAS 算法 |
innodb事务(Transaction)
事务4个特性:ACID
- 事务的原子性是通过undo log来实现的
- 事务的持久性性是通过redo log来实现的
- 事务的隔离性是通过(读写锁 + MVCC)来实现的,隔离性是要管理多个并发读写请求的访问顺序。这种顺序包括串行或者是并行
- 事务的一致性是通过原子性,持久性,隔离性来实现的
事务的隔离性&隔离级别
- 脏读:事务A修改了某个记录,然后事务B去读取,然后事务A撤销了事务,那么事务B就读取到了脏数据
- 不可重复读:事务A前后两次读取到的内容不一样,因为读的过程中另一个事务B有修改操作,虽然B可能撤销事务
- 幻读:事务A操作全表,然而事务B操作了数据库,比如新增一条记录,事务A本来修改了所有,但发现还有记录没有修改,产生幻觉一样
可重复读和脏读的区别是:脏读是某一事务读取了另一个事务未提交的脏数据,而可重复读则是读取了前一事务提交的数据。
| 隔离级别 | 脏读 | 可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable read(MySQL默认) | × | × | √ |
| Serializable | × | × | × |
- √: 可能出现; ×: 不会出现
MySql隔离级别的实现方式
- LBCC: Lock-Based Concurrent Control
- MVCC: Multi-Version Concurrent Control
mvcc(Multiversion concurrency control)
MVCC全称是: Multiversion concurrency control,多版本并发控制,一般在数据库管理系统中,多事务情况下,实现对数据库的并发访问;其主要是为了提高并发的读写性能,不用加锁就能让多个事物并发读写
即:MVCC就是为了实现读-写冲突不加锁,而这个读指的就是快照读, 而非当前读(当前读实际上是一种加锁的操作),是乐观锁的实现
MVCC 在读已提交(Read Committed)和可重复读(Repeatable Read)隔离级别下起作用
考虑场景:程序员A正在读数据库中某些内容,而程序员B正在给这些内容做修改(假设是在一个事务内修改,大概持续10s左右),A在这10s内 则可能看到一个不一致的数据;在B没有提交前,如何让A能够一直读到的数据都是一致的呢?
- 基于锁的并发控制:程序员B开始修改数据时,给这些数据加上锁,程序员A这时再读,就发现读取不了,处于等待情况,只能等B操作完才能读数据,这保证A不会读到一个不一致的数据,但是这个会影响程序的运行效率。
- MVCC:每个用户连接数据库时,看到的都是某一特定时刻的数据库快照,在B的事务没有提交之前,A始终读到的是某一特定时刻的数据库快照,不会读到B事务中的数据修改情况,直到B事务提交,才会读取B的修改内容。
mvcc的核心实现(只在Read committed,Repeatable read两个隔离级别工作):
- 表的隐藏列: 记录事务id以及上个版本数据地址(DB_TRX_ID,DB_ROLL_PTR)
- undo log: 记录数据各个版本修改历史
read view: 读视图(【已提交事务】【未提交与已提交事务】【未开始事务】),用于判断哪些版本对当前事务是可见的
- 由未提交的事务ID数组,最小最大事务ID,最大事务ID组成:
- 不在未提交的事务数组中,并且事务Id小于Max或者是自己,则对于当前事务是可见的
A 6-byte DB_TRX_ID field indicates the transaction identifier for the last transaction that inserted or updated the row. Also, a deletion is treated internally as an update where a special bit in the row is set to mark it as deleted.(DB_TRX_ID是该行记录当前的事务id)
A 7-byte DB_ROLL_PTR field called the roll pointer. The roll pointer points to an undo log record written to the rollback segment. If the row was updated, the undo log record contains the information necessary to rebuild the content of the row before it was updated.(DB_ROLL_PTR指向该行在undo log中的位置)
A 6-byte DB_ROW_ID field contains a row ID that increases monotonically as new rows are inserted. If InnoDB generates a clustered index automatically, the index contains row ID values. Otherwise, the DB_ROW_ID column does not appear in any index.
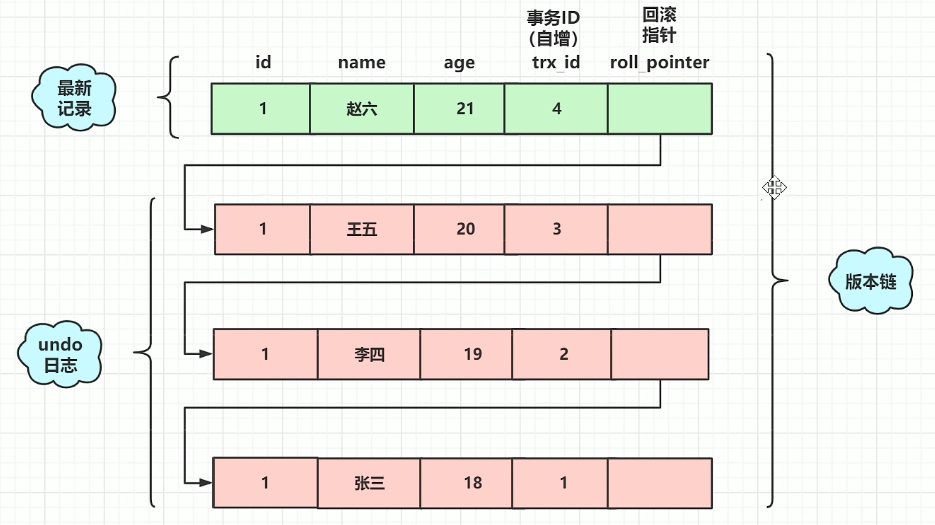
- m_ids:活跃的事务就是指还没有commit的事务
- max_trx_id:例如m_ids中的事务id为(1,2,3),那么下一个应该分配的事务id就是4,max_trx_id就是4
creator_trx_id:执行select读这个操作的事务的id
RC的隔离级别下,每个快照读都会生成并获取最新的readview。
- RR的隔离级别下,只有在同一个事务的第一个快照读才会创建readview,之后的每次快照读都使用的同一个readview,所以每次的查询结果都是一样的。
数据库之InnoDB可重复读隔离级别下如何避免幻读?
- 什么是当前读:当前读就是加了锁的增删改查语句
- 什么是快照读:快照读读到的有可能不是数据的最新版本,可能是之前的历史版本
- 什么是mvcc:多版本并发控制(不加锁,事务是多版本的,解决并发读写)
CREATE TABLE `account_innodb` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`balance` int(11) DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into account_innodb(`name`, `balance`) values('test1', 1000);
insert into account_innodb(`name`, `balance`) values('test2', 600);
- Repeatable read(MySQL默认)隔离级别下

如果事务2直接完成,而事务1开始事务后,读的时候在事务2完成之后,那么快照读能读到最新的版本数据
mysql> start TRANSACTION;
Query OK, 0 rows affected (0.00 sec)
mysql> update account_innodb set balance = 900 where id = 2;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
Query OK, 0 rows affected (0.01 sec)
mysql>
RR级别下的快照读跟它什么时候执行有关
RC、RR级别下的InnoDB的非阻塞读(快照读)如何实现?
- 回顾:undo log是干什么的
undo log用于存放数据被修改前的值,假设修改 tba 表中 id=2的行数据,把Name='B' 修改为Name ='B2' ,那么undo日志就会用来存放之前Name='B'的记录,如果这个修改出现异常,可以使用undo日志来实现回滚操作,保证事务的一致性。
- read view ?
Read View就是事务进行快照读操作的时候生产的读视图(Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的ID(当每个事务开启时,都会被分配一个ID, 这个ID是递增的,所以最新的事务,ID值越大)
它决定的是当前事务能看到的是哪个事务操作前的数据。它遵循一个可见性算法:将要修改的数据事务的DB_TRX_ID取出来与系统其它事务活跃ID做对比,如果大于或者等于这些ID,那么就取出当前DB_TRX_ID的事务的DB_ROLL_PTR指针所指向的undo log的版本数据,直到DB_TRX_ID小于这些系统活跃事务的ID,这样即可取到稳定的数据。注意(每当进入一个transaction时,事务ID就会增大)

- 回顾:为什么RC、RR级别下的快照读有区别?
在RC级别下,快照读每调用一次,那么以上的Undo log操作就会执行一次,里面的版本数据就会更新到最新。而在RR级别下,我们第一次调用快照读,创建了Undo log,后边是不会再执行,直到提交事务;RR级别下,后面读取的都是最开始的,所以可以做到避免幻读;而RC不可以避免幻读。
InnoDB的RR及以上级别避免幻读的内在是next-key锁(行锁和间隙锁组合起来)
- 行锁(Record Lock): 对索引记录加锁。
- gap锁是间隙锁,即锁定一个范围,但不包括记录本身,它的目的是为了防止事务的两次当前读产生幻读;gap锁上锁条件:
- 如果where条件全部命中,则不会用Gap锁,只会加记录锁
- 如果where条件部分命中或者全不命中,则会加Gap锁
- 如果sql走的是非唯一索引或者不走索引,则会加Gap锁
原子性:undo log
An undo log is a collection of undo log records associated with a single read-write transaction. An undo log record contains information about how to undo the latest change by a transaction to a clustered index record. If another transaction needs to see the original data as part of a consistent read operation, the unmodified data is retrieved from undo log records. Undo logs exist within undo log segments, which are contained within rollback segments. Rollback segments reside in undo tablespaces and in the global temporary tablespace.
undo log是逻辑日志。可以理解为:只要有insert操作,就可以记录一条delete记录;有delete操作,就记录一条insert记录,有update操作,则有一条记录能回到更新前数据的update操作;这样恢复操作直接去执行,就能回到事务之前的状态
undo log是为了实现事务的原子性,在Mysql数据库Innodb存储引擎中,还用undo log来实现多版本并发控制(MVCC)
在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为undo log);然后进行数据的修改。如果出现了错误或者用户执行了rollback,系统利用undo log的备份数据将数据恢复到事务开始之前的状态
undo log 相关参数
mysql> show global variables like '%undo%';
+--------------------------+------------+
| Variable_name | Value |
+--------------------------+------------+
| innodb_max_undo_log_size | 1073741824 |
| innodb_undo_directory | ./ |
| innodb_undo_log_truncate | OFF |
| innodb_undo_logs | 128 |
| innodb_undo_tablespaces | 0 |
+--------------------------+------------+
5 rows in set (0.05 sec)
mysql> show global variables like '%truncate%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| innodb_purge_rseg_truncate_frequency | 128 |
| innodb_undo_log_truncate | OFF |
+--------------------------------------+-------+
2 rows in set (0.00 sec)
mysql>
innodb_max_undo_log_size
控制最大undo tablespace文件的大小,当启动了innodb_undo_log_truncate 时,undo tablespace 超过innodb_max_undo_log_size 阀值时才会去尝试truncate。该值默认大小为1G,truncate后的大小默认为10M。
innodb_undo_tablespaces
设置undo独立表空间个数,范围为0-128, 默认为0,0表示表示不开启独立undo表空间 且 undo日志存储在ibdata文件中。该参数只能在最开始初始化MySQL实例的时候指定,如果实例已创建,这个参数是不能变动的,如果在数据库配置文 件 .cnf 中指定innodb_undo_tablespaces 的个数大于实例创建时的指定个数,则会启动失败,提示该参数设置有误。如果设置了该参数为n(n>0),那么就会在undo目录下创建n个undo文件(undo001,undo002 ...... undo n),每个文件默认大小为10M.
什么时候需要来设置这个参数呢? 当DB写压力较大时,可以设置独立UNDO表空间,把UNDO LOG从ibdata文件中分离开来,指定 innodb_undo_directory目录存放,可以指定到高速磁盘上,加快UNDO LOG 的读写性能。
innodb_undo_log_truncate
InnoDB的purge线程,根据innodb_undo_log_truncate设置开启或关闭、innodb_max_undo_log_size的参数值,以及truncate的频率来进行空间回收和 undo file 的重新初始化。
innodb_purge_rseg_truncate_frequency
用于控制purge回滚段的频度,默认为128。假设设置为n,则说明,当Innodb Purge操作的协调线程 purge事务128次时,就会触发一次History purge,检查当前的undo log 表空间状态是否会触发truncate。
持久性:redo log
The redo log is a disk-based data structure used during crash recovery to correct data written by incomplete transactions. During normal operations, the redo log encodes requests to change table data that result from SQL statements or low-level API calls. Modifications that did not finish updating data files before an unexpected shutdown are replayed automatically during initialization and before connections are accepted.
The redo log is physically represented on disk by redo log files. Data that is written to redo log files is encoded in terms of records affected, and this data is collectively referred to as redo. The passage of data through redo log files is represented by an ever-increasing LSN value. Redo log data is appended as data modifications occur, and the oldest data is truncated as the checkpoint progresses.
和undo log相反,redo log记录的是新数据的备份,当事务提交前,只要将redo log持久化即可,不需要将数据持久化,当系统崩溃时,虽然数据没有持久化,但是redo log已经持久化,系统可以根据redo log的内容,将所有数据恢复到最新的状态。
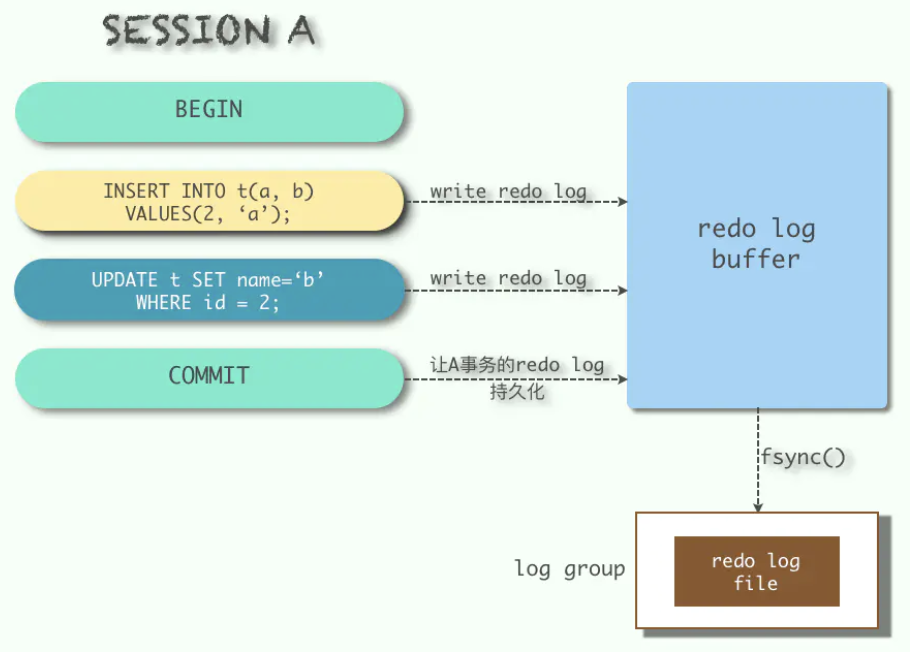
redo log记录的物理格式日志,其记录的是对于每个页的修改,记录了事务的行为
有些操作会产生多条 redo 日志,并且还需要保证是原子的,比如在B+树二级索引中插入一条记录,可能会产生很多条redo日志(比如页分裂的情况),为了保证原子性,多条redo日志会以组的形式记录,在这组redo日志后面会加上一条特殊类型的redo日志,表示前面是一组完整的redo日志。如果是单个日志,在日志的type字段里会有一个比特位来表示是一条单一的redo日志。
redo log持久化策略
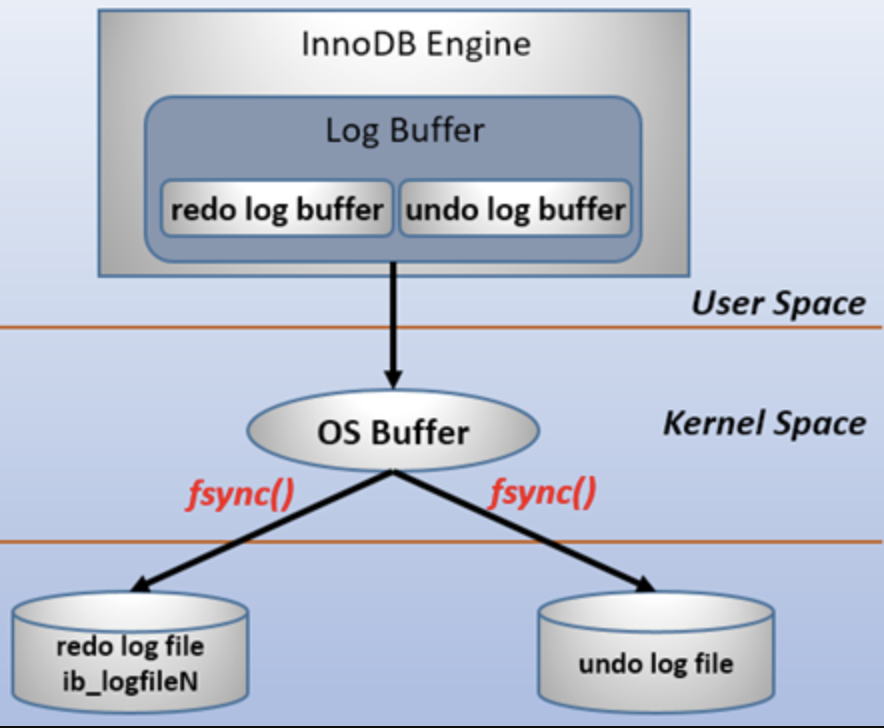
mysql进程挂?机器挂?性能问题考虑?数据一致性考虑?
- 0:只写redo log,每秒落地一次,性能最高,数据一致性最差,如果mysql奔溃可能丢失一秒的数据(master thread每隔1秒进行一次fsync系统调用操作)
- 1:表示每次事务提交时进行写redo log file的操作,性能最差,一致性最高(mysql默认值)
- 2:写redo log,buffer同时写入到os buffer,性能好,安全性也高,只要os不宕机就能保证数据一致性(不进行fsync操作)
隔离性:通过加锁(当前读)&MVCC(快照读)实现
一致性:通过undolog、redolog、隔离性共同实现
主从复制
为什么需要主从复制?
- 当主数据库出现问题时,可以用从数据库代替主数据库,可以避免数据的丢失(数据热备)
- 减轻主数据库的压力,降低单机的磁盘I/O访问率,提高单个机器的I/O性能
- 在业务复杂的系统中,有这么一个情景,有一句sql语句需要锁表,导致暂时不能使用读的服务,那么就很影响运行中的业务,使用主从复制,让主库负责写、从库负责读;这样,即使主库出现了锁表的情景,也能通过读从库也去保证业务的正常运作(读写分离)
主从复制的原理?
- 主服务器上面的任何修改都会通过自己的
I/O thread(I/O 线程)保存在二进制日志Binary log里面 - 主服务器的binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程然后发送binlog内容到从库;对于每一个即将发送给从库的sql事件,binlog输出线程会将其锁住。一旦该事件被线程读取完之后,该锁会被释放,即使在该事件完全发送到从库的时候,该锁也会被释放
- 从服务器上面也启动一个
I/O thread,通过配置好的用户名和密码, 连接到主服务器上面请求读取二进制日志,然后把读取到的二进制日志写到本地的一个Relay log(中继日志)里面 - 从服务器上面同时开启一个
SQL thread定时检查Relay log(这个文件也是二进制的),如果发现有更新立即把更新的内容在本机的数据库上面执行一遍

基本步骤如下(注意整个mysql主从复制是异步的)
* 步骤一:主库db的更新事件(update、insert、delete)被写到binlog
* 步骤二:从库发起连接,连接到主库
* 步骤三:此时主库创建一个binlog dump thread,把binlog的内容发送到从库
* 步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log
* 步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db
binlog文件
binlog文件概述
- 查看是否开启binlog
show variables like 'log_bin';
binlog是二进制日志文件,是由mysql server维护的用于记录mysql的数据更新或者潜在更新(比如DELETE语句执行删除而实际并没有符合条件的数据),在mysql主从复制中就是依靠的binlog;执行SELECT等不涉及数据更新的语句是不会记binlog的,而涉及到数据更新则会记录。要注意的是,对支持事务的引擎如innodb而言,必须要提交了事务才会记录binlog。
The binary log is a set of log files that contain information about data modifications made to a MySQL server instance. The log is enabled by starting the server with the --log-bin option.
binlog文件作用
The binary log has two important purposes:
For replication, the binary log is used on master replication servers as a record of the statements to be sent to slave servers. Many details of binary log format and handling are specific to this purpose. The master server sends the events contained in its binary log to its slaves, which execute those events to make the same data changes that were made on the master. A slave stores events received from the master in its relay log until they can be executed. The relay log has the same format as the binary log.
Certain data recovery operations require use of the binary log. After a backup file has been restored, the events in the binary log that were recorded after the backup was made are re-executed. These events bring databases up to date from the point of the backup.
主从复制 & 数据恢复
binlog文件记录类型
Statement-based logging: Events contain SQL statements that produce data changes (inserts, updates, deletes)
Row-based logging: Events describe changes to individual rows
Mixed logging uses statement-based logging by default but switches to row-based logging automatically as necessary.
| format | 定义 | 优点 | 缺点 |
|---|---|---|---|
| statement | 记录修改的sql语句 | 日志文件小,节约IO,提高性能 | 准确性差,对一些系统函数不能准确复制或不能复制,如now()、uuid()、limit(由于mysql是自选索引,有可能master同salve选择的索引不同,导致更新的内容也不同)等;在某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题) |
| row | 记录的是每行实际数据的变更 | 准确性强,能准确复制数据的变更 | 日志文件大,较大的网络IO和磁盘IO |
| mixed | statement和row模式的混合 | 准确性强,文件大小适中 | 当binlog format 设置为mixed时,普通复制不会有问题,但是级联复制在特殊情况下会binlog丢失 |
- 查看 binlog 格式

业内目前推荐使用的是row模式,准确性高,虽然文件大,但是现在有SSD和万兆光纤网络,这些磁盘IO和网络IO都是可以接受的。
分库/分表
为什么会分表分库?
支撑高并发、大数据量
经验值:单表到几百万记录,存储几百G的时候,性能就会相对差一些了
分表 & 分库概念
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
分库分表包括分库和分表两个部分,在生产中通常包括:垂直分库、水平分库、垂直分表、水平分表四种方式。
垂直分表
用户在浏览商品列表时,只有对某商品感兴趣时才会查看该商品的详细描述。因此,商品信息中商品描述字段访问频次较低,且该字段存储占用空间较大,访问单个数据IO时间较长;商品信息中商品名称、商品图片、商品价格等其它字段数据访问频次较高。由于这两种数据的特性不一样,因此考虑将商品信息表拆分成:将访问频次低的商品描述信息单独存放在一张表中,访问频次较高的商品基本信息单独放在一张表中;即 商品表 可拆分成 商品信息表 和 商品描述表。
垂直分表定义:类似大宽表变成小表(比如高频访问字段)+稍宽表(比如低频访问的大字段)的形式
- 为什么大字段IO效率低
- 第一是由于数据量本身大,需要更长的读取时间;
- 第二是跨页,页是数据库存储单位,很多查找及定位操作都是以页为单位,单页内的数据行越多数据库整体性能越好,而大字段占用空间大,单页内存储行数少,因此IO效率较低。
- 第三,数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
垂直分库(不同业务表存到到多个数据库中)
通过垂直分表性能得到了一定程度的提升,但是还没有达到要求,并且磁盘空间也快不够了,因为数据还是始终限制在一台服务器,库内垂直分表只解决了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。可以业务划分:将商品业务,卖家业务,用户信息,存储到不同到数据服务器上
垂直分库:是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
- 垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题。
水平分库
经过垂直分库后,数据库性能问题得到一定程度的解决,但是随着业务量的增长,PRODUCT_DB(商品库)单库存储数据已经超出预估。可以将商品的所属店铺ID为单数的和店铺ID为双数的商品信息分别放在两个数据库中
水平分库:是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
它带来的提升是:
- 解决了单库大数据,高并发的性能瓶颈
- 提高了系统的稳定性及可用性
例如:要操作某条商品数据,先分析这条数据所属的店铺ID。如果店铺ID为双数,将此操作映射至RRODUCT_DB1(商品库1);如果店铺ID为单数,将操作映射至RRODUCT_DB2(商品库2)。此操作要访问数据库名称的表达式为RRODUCT_DB[店铺ID%2 + 1] 。
水平分表
按照水平分库的思路把PRODUCT_DB_X(商品库)内的表也可以进行水平拆分,其目的也是为解决单表数据量大的问题,与水平分库的思路类似,不过这次操作的目标是表
水平分表:是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中
分库分表带来的问题
- 事务的一致性问题:分布式事务
- 跨节点关联查询问题
- 跨节点分页,排序问题
- 主键重复问题:全局ID
- 公共表,高频公共操作表